 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating artificial texts as substitution or complement of training data
Paper and Code

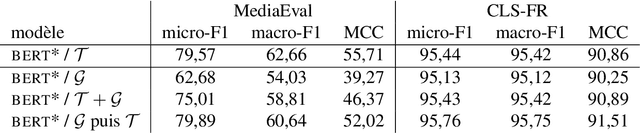

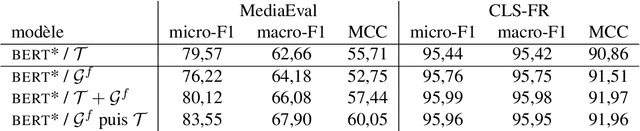
The quality of artificially generated texts has considerably improved with the advent of transformers. The question of using these models to generate learning data for supervised learning tasks naturally arises. In this article, this question is explored under 3 aspects: (i) are artificial data an efficient complement? (ii) can they replace the original data when those are not available or cannot be distributed for confidentiality reasons? (iii) can they improve the explainability of classifiers? Different experiments are carried out on Web-related classification tasks -- namely sentiment analysis on product reviews and Fake News detection -- using artificially generated data by fine-tuned GPT-2 models. The results show that such artificial data can be used in a certain extend but require pre-processing to significantly improve performance. We show that bag-of-word approaches benefit the most from such data augmentation.