 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLhotse: a speech data representation library for the modern deep learning ecosystem
Paper and Code
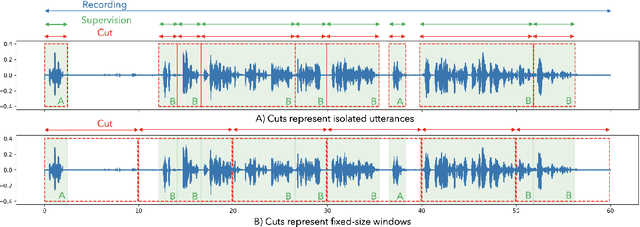
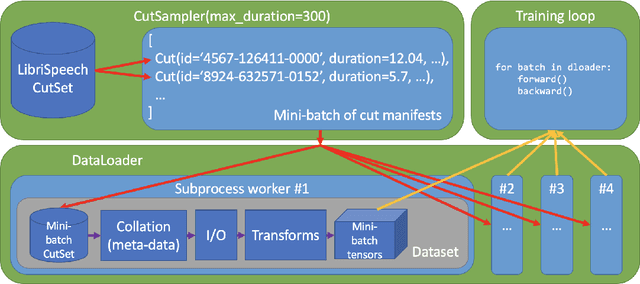
Speech data is notoriously difficult to work with due to a variety of codecs, lengths of recordings, and meta-data formats. We present Lhotse, a speech data representation library that draws upon lessons learned from Kaldi speech recognition toolkit and brings its concepts into the modern deep learning ecosystem. Lhotse provides a common JSON description format with corresponding Python classes and data preparation recipes for over 30 popular speech corpora. Various datasets can be easily combined together and re-purposed for different tasks. The library handles multi-channel recordings, long recordings, local and cloud storage, lazy and on-the-fly operations amongst other features. We introduce Cut and CutSet concepts, which simplify common data wrangling tasks for audio and help incorporate acoustic context of speech utterances. Finally, we show how Lhotse leverages PyTorch data API abstractions and adopts them to handle speech data for deep learning.