 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta-learning via Language Model In-context Tuning
Paper and Code
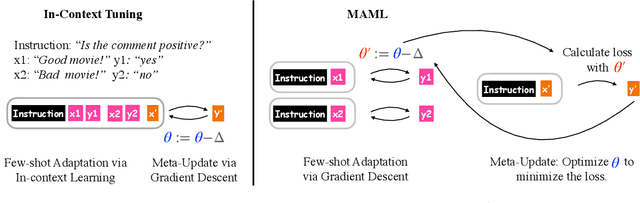
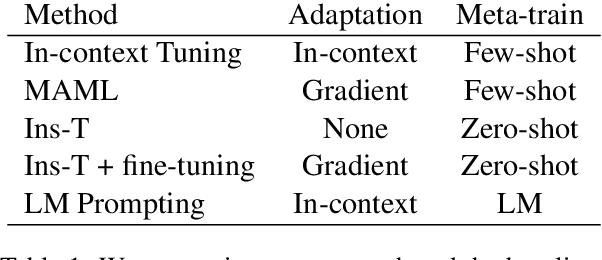
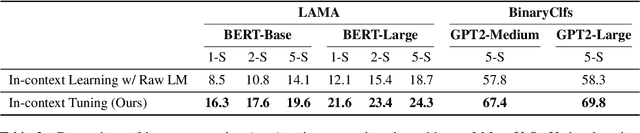
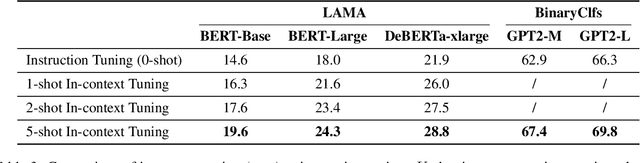
The goal of meta-learning is to learn to adapt to a new task with only a few labeled examples. To tackle this problem in NLP, we propose $\textit{in-context tuning}$, which recasts adaptation and prediction as a simple sequence prediction problem: to form the input sequence, we concatenate the task instruction, the labeled examples, and the target input to predict; to meta-train the model to learn from in-context examples, we fine-tune a pre-trained language model (LM) to predict the target label from the input sequences on a collection of tasks. We benchmark our method on two collections of text classification tasks: LAMA and BinaryClfs. Compared to first-order MAML which adapts the model with gradient descent, our method better leverages the inductive bias of LMs to perform pattern matching, and outperforms MAML by an absolute $6\%$ AUC ROC score on BinaryClfs, with increasing advantage w.r.t. model size. Compared to non-fine-tuned in-context learning (i.e. prompting a raw LM), in-context tuning directly learns to learn from in-context examples. On BinaryClfs, in-context tuning improves the average AUC-ROC score by an absolute $10\%$, and reduces the variance with respect to example ordering by 6x and example choices by 2x.