 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePTQ-SL: Exploring the Sub-layerwise Post-training Quantization
Paper and Code
Oct 18, 2021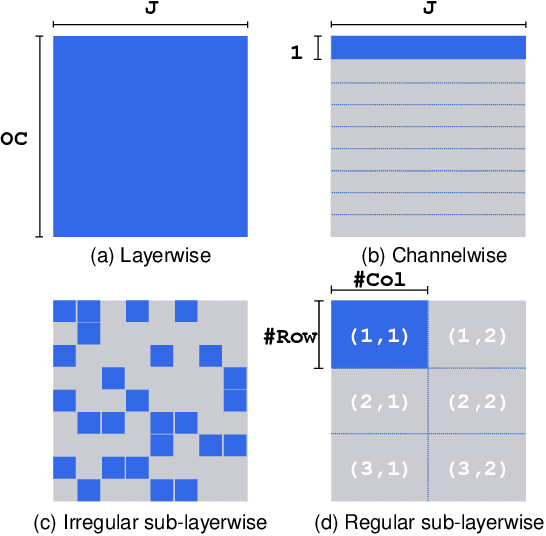
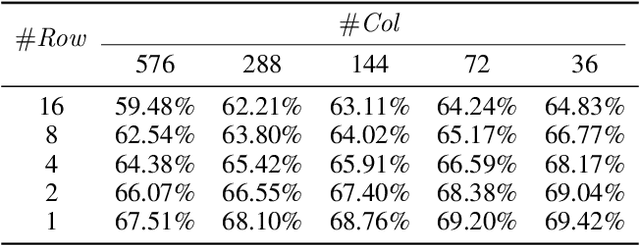
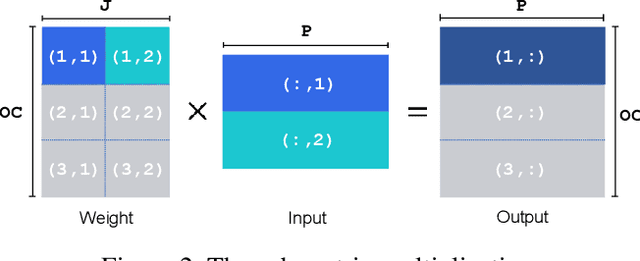
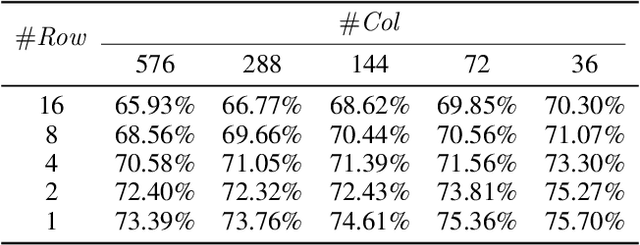
Network quantization is a powerful technique to compress convolutional neural networks. The quantization granularity determines how to share the scaling factors in weights, which affects the performance of network quantization. Most existing approaches share the scaling factors layerwisely or channelwisely for quantization of convolutional layers. Channelwise quantization and layerwise quantization have been widely used in various applications. However, other quantization granularities are rarely explored. In this paper, we will explore the sub-layerwise granularity that shares the scaling factor across multiple input and output channels. We propose an efficient post-training quantization method in sub-layerwise granularity (PTQ-SL). Then we systematically experiment on various granularities and observe that the prediction accuracy of the quantized neural network has a strong correlation with the granularity. Moreover, we find that adjusting the position of the channels can improve the performance of sub-layerwise quantization. Therefore, we propose a method to reorder the channels for sub-layerwise quantization. The experiments demonstrate that the sub-layerwise quantization with appropriate channel reordering can outperform the channelwise quantization.