 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Purification through Representation Disentanglement
Paper and Code
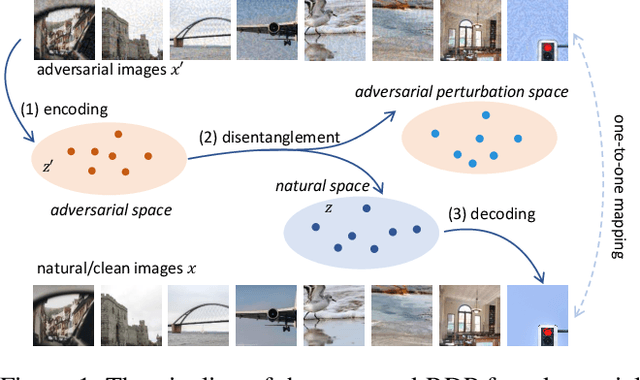
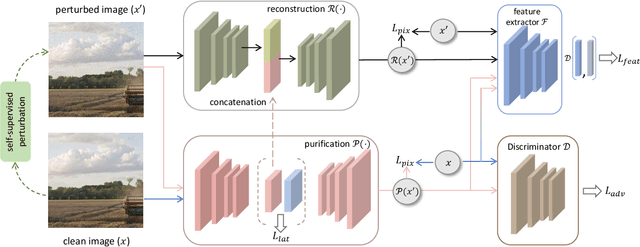
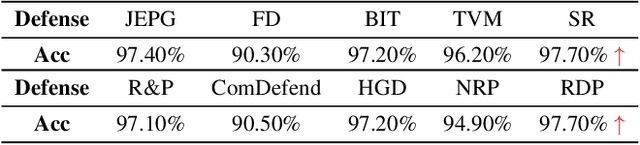

Deep learning models are vulnerable to adversarial examples and make incomprehensible mistakes, which puts a threat on their real-world deployment. Combined with the idea of adversarial training, preprocessing-based defenses are popular and convenient to use because of their task independence and good generalizability. Current defense methods, especially purification, tend to remove ``noise" by learning and recovering the natural images. However, different from random noise, the adversarial patterns are much easier to be overfitted during model training due to their strong correlation to the images. In this work, we propose a novel adversarial purification scheme by presenting disentanglement of natural images and adversarial perturbations as a preprocessing defense. With extensive experiments, our defense is shown to be generalizable and make significant protection against unseen strong adversarial attacks. It reduces the success rates of state-of-the-art \textbf{ensemble} attacks from \textbf{61.7\%} to \textbf{14.9\%} on average, superior to a number of existing methods. Notably, our defense restores the perturbed images perfectly and does not hurt the clean accuracy of backbone models, which is highly desirable in practice.