 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImprove Cross-lingual Voice Cloning Using Low-quality Code-switched Data
Paper and Code
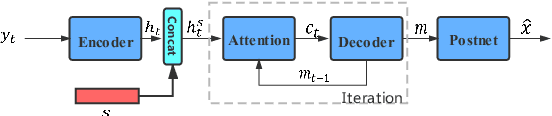
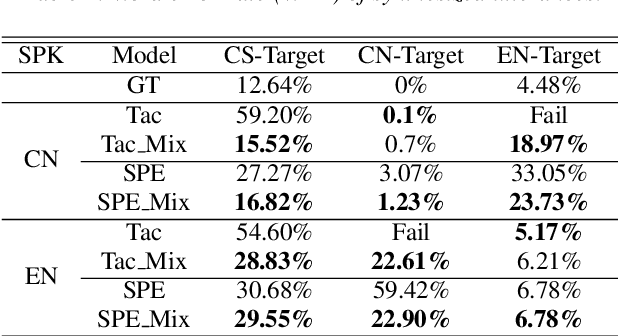
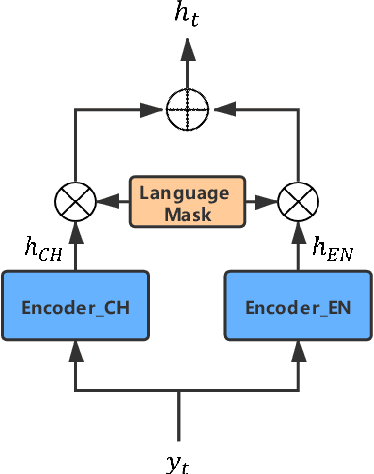
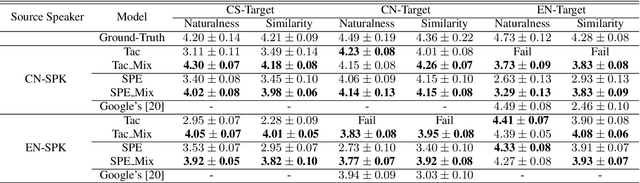
Recently, sequence-to-sequence (seq-to-seq) models have been successfully applied in text-to-speech (TTS) to synthesize speech for single-language text. To synthesize speech for multiple languages usually requires multi-lingual speech from the target speaker. However, it is both laborious and expensive to collect high-quality multi-lingual TTS data for the target speakers. In this paper, we proposed to use low-quality code-switched found data from the non-target speakers to achieve cross-lingual voice cloning for the target speakers. Experiments show that our proposed method can generate high-quality code-switched speech in the target voices in terms of both naturalness and speaker consistency. More importantly, we find that our method can achieve a comparable result to the state-of-the-art (SOTA) performance in cross-lingual voice cloning.