Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInjecting Text and Cross-lingual Supervision in Few-shot Learning from Self-Supervised Models
Paper and Code
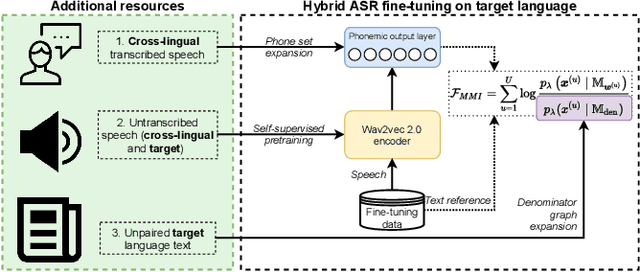

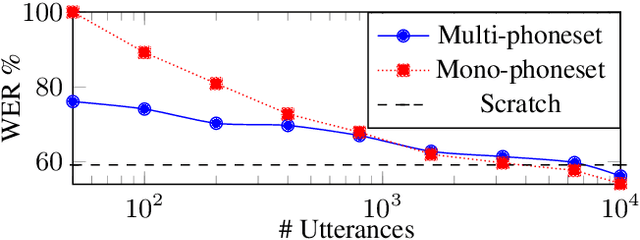
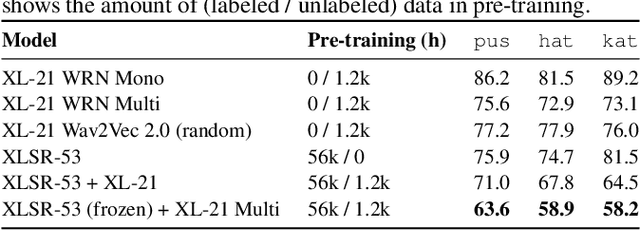
Self-supervised model pre-training has recently garnered significant interest, but relatively few efforts have explored using additional resources in fine-tuning these models. We demonstrate how universal phoneset acoustic models can leverage cross-lingual supervision to improve transfer of pretrained self-supervised representations to new languages. We also show how target-language text can be used to enable and improve fine-tuning with the lattice-free maximum mutual information (LF-MMI) objective. In three low-resource languages these techniques greatly improved few-shot learning performance.
* \c{opyright} 2021 IEEE. Personal use of this material is permitted.
Permission from IEEE must be obtained for all other uses, in any current or
future media, including reprinting/republishing this material for advertising
or promotional purposes, creating new collective works, for resale or
redistribution to servers or lists, or reuse of any copyrighted component of
this work in other works
View paper on