Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixer-TTS: non-autoregressive, fast and compact text-to-speech model conditioned on language model embeddings
Paper and Code
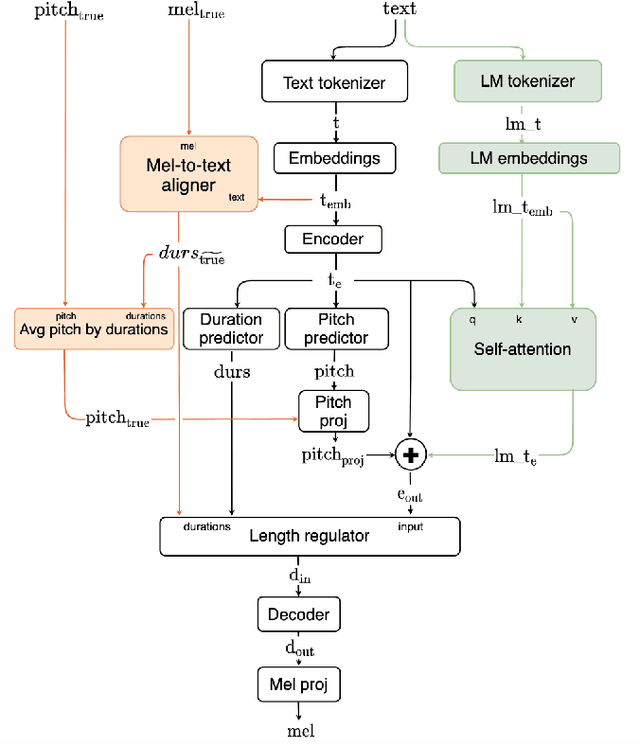
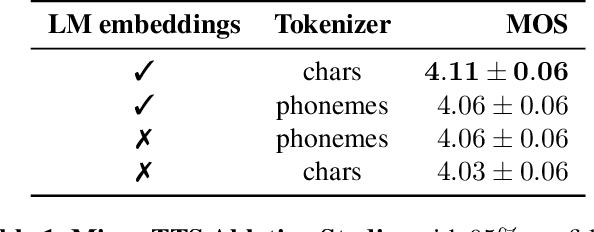
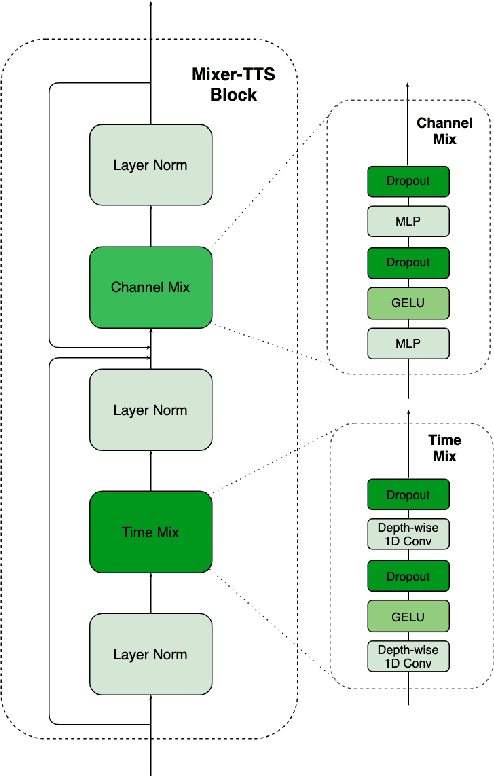
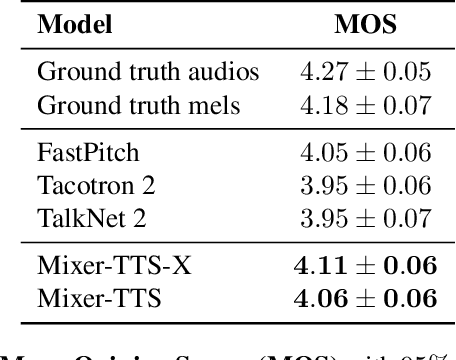
This paper describes Mixer-TTS, a non-autoregressive model for mel-spectrogram generation. The model is based on the MLP-Mixer architecture adapted for speech synthesis. The basic Mixer-TTS contains pitch and duration predictors, with the latter being trained with an unsupervised TTS alignment framework. Alongside the basic model, we propose the extended version which additionally uses token embeddings from a pre-trained language model. Basic Mixer-TTS and its extended version achieve a mean opinion score (MOS) of 4.05 and 4.11, respectively, compared to a MOS of 4.27 of original LJSpeech samples. Both versions have a small number of parameters and enable much faster speech synthesis compared to the models with similar quality.
* Preprint. Submitted to ICASSP-22
View paper on