 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End Supermask Pruning: Learning to Prune Image Captioning Models
Paper and Code
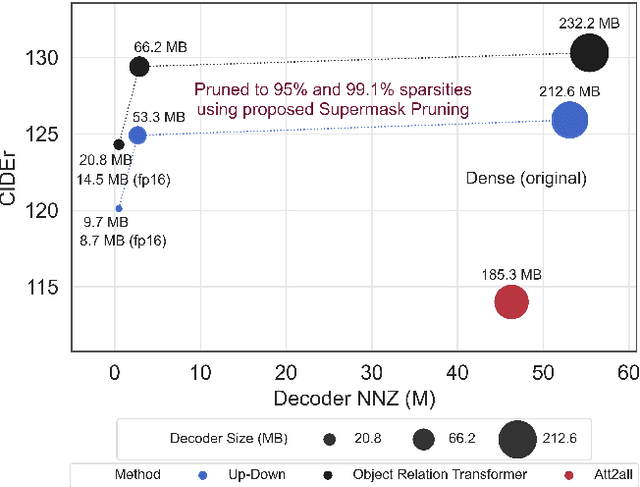
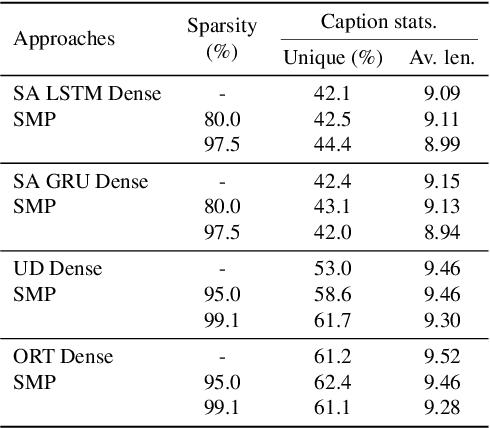
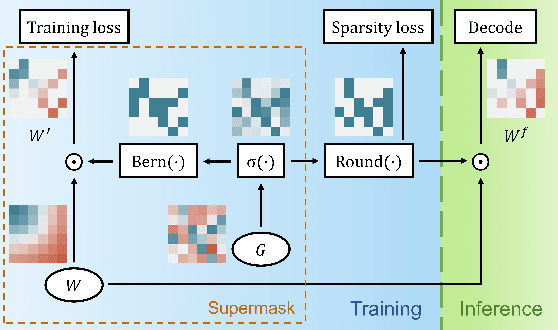
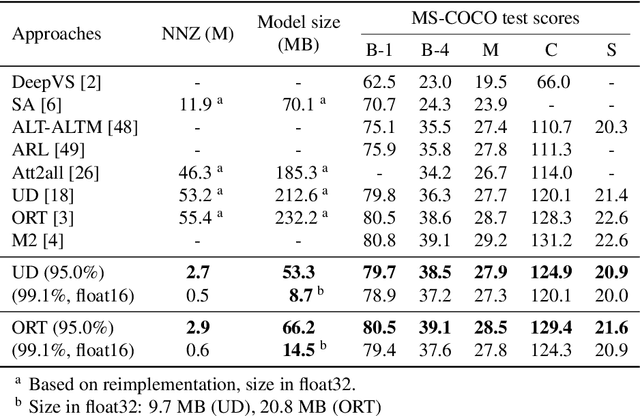
With the advancement of deep models, research work on image captioning has led to a remarkable gain in raw performance over the last decade, along with increasing model complexity and computational cost. However, surprisingly works on compression of deep networks for image captioning task has received little to no attention. For the first time in image captioning research, we provide an extensive comparison of various unstructured weight pruning methods on three different popular image captioning architectures, namely Soft-Attention, Up-Down and Object Relation Transformer. Following this, we propose a novel end-to-end weight pruning method that performs gradual sparsification based on weight sensitivity to the training loss. The pruning schemes are then extended with encoder pruning, where we show that conducting both decoder pruning and training simultaneously prior to the encoder pruning provides good overall performance. Empirically, we show that an 80% to 95% sparse network (up to 75% reduction in model size) can either match or outperform its dense counterpart. The code and pre-trained models for Up-Down and Object Relation Transformer that are capable of achieving CIDEr scores >120 on the MS-COCO dataset but with only 8.7 MB and 14.5 MB in model size (size reduction of 96% and 94% respectively against dense versions) are publicly available at https://github.com/jiahuei/sparse-image-captioning.