 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistilHuBERT: Speech Representation Learning by Layer-wise Distillation of Hidden-unit BERT
Paper and Code
Oct 06, 2021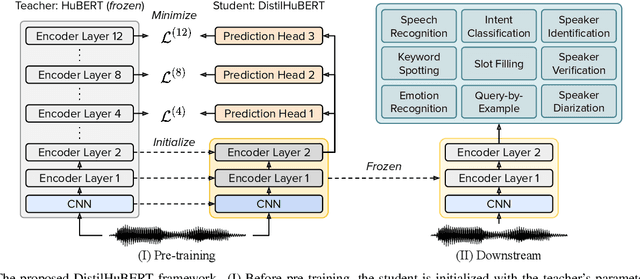
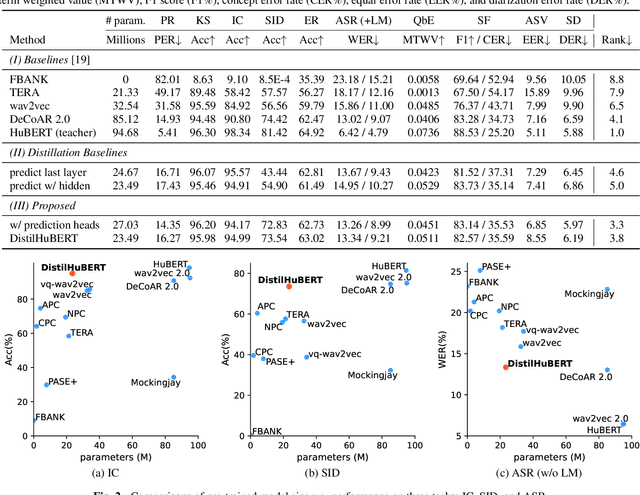
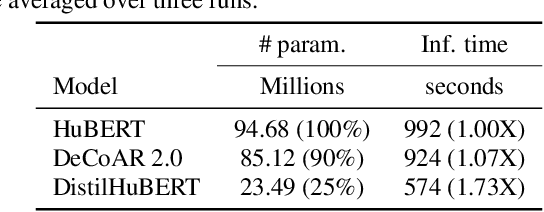
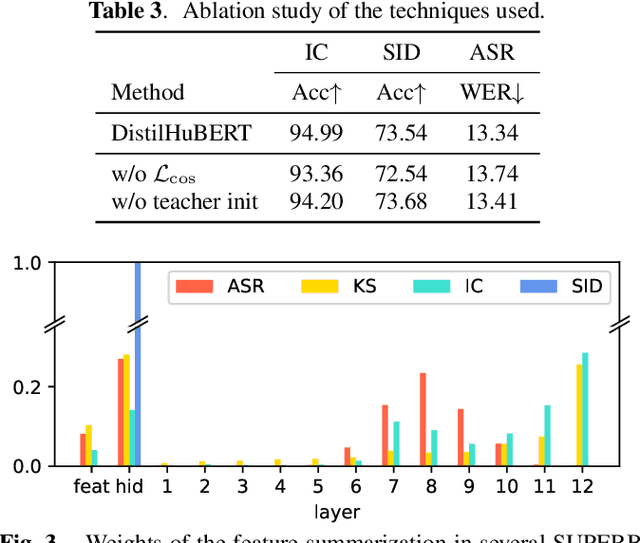
Self-supervised speech representation learning methods like wav2vec 2.0 and Hidden-unit BERT (HuBERT) leverage unlabeled speech data for pre-training and offer good representations for numerous speech processing tasks. Despite the success of these methods, they require large memory and high pre-training costs, making them inaccessible for researchers in academia and small companies. Therefore, this paper introduces DistilHuBERT, a novel multi-task learning framework to distill hidden representations from a HuBERT model directly. This method reduces HuBERT's size by 75% and 73% faster while retaining most performance in ten different tasks. Moreover, DistilHuBERT required little training time and data, opening the possibilities of pre-training personal and on-device SSL models for speech.