Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Arabic Diacritization by Learning to Diacritize and Translate
Paper and Code
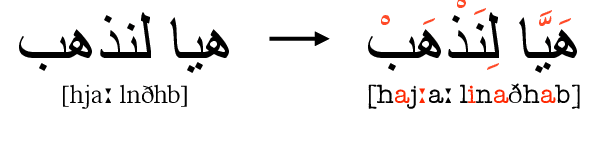

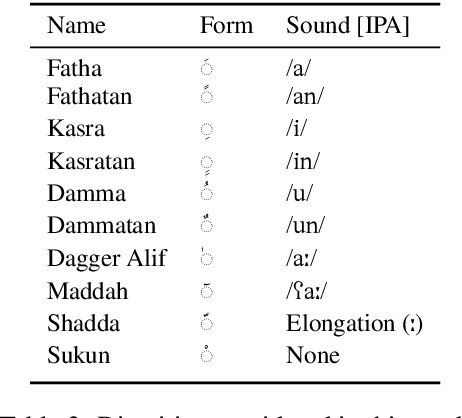
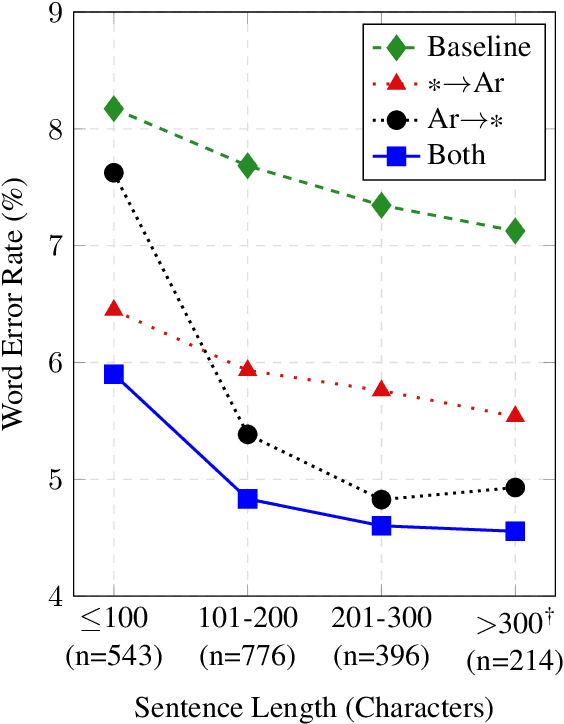
We propose a novel multitask learning method for diacritization which trains a model to both diacritize and translate. Our method addresses data sparsity by exploiting large, readily available bitext corpora. Furthermore, translation requires implicit linguistic and semantic knowledge, which is helpful for resolving ambiguities in the diacritization task. We apply our method to the Penn Arabic Treebank and report a new state-of-the-art word error rate of 4.79%. We also conduct manual and automatic analysis to better understand our method and highlight some of the remaining challenges in diacritization.
View paper on