 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan We Leverage Predictive Uncertainty to Detect Dataset Shift and Adversarial Examples in Android Malware Detection?
Paper and Code
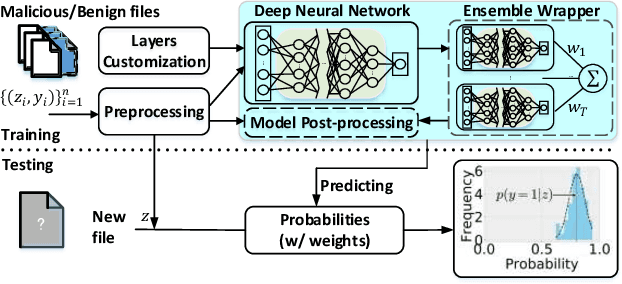
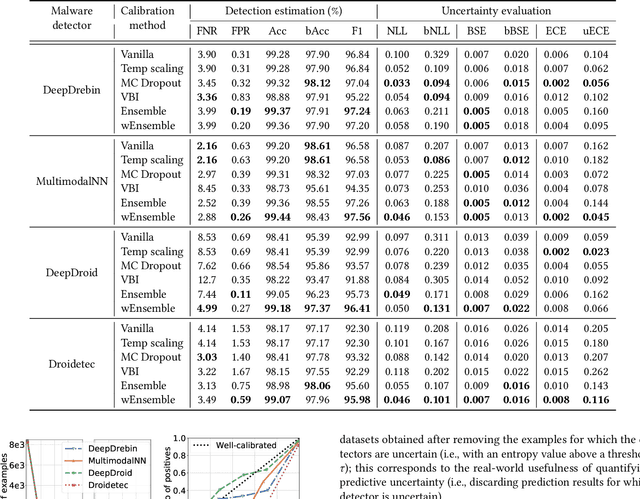
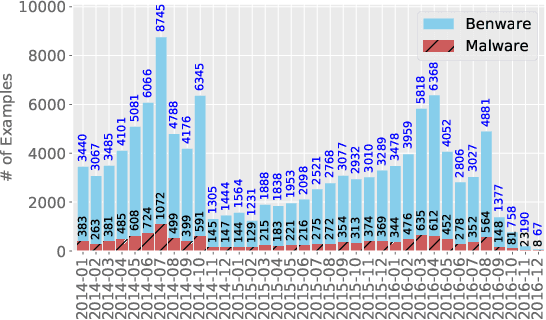
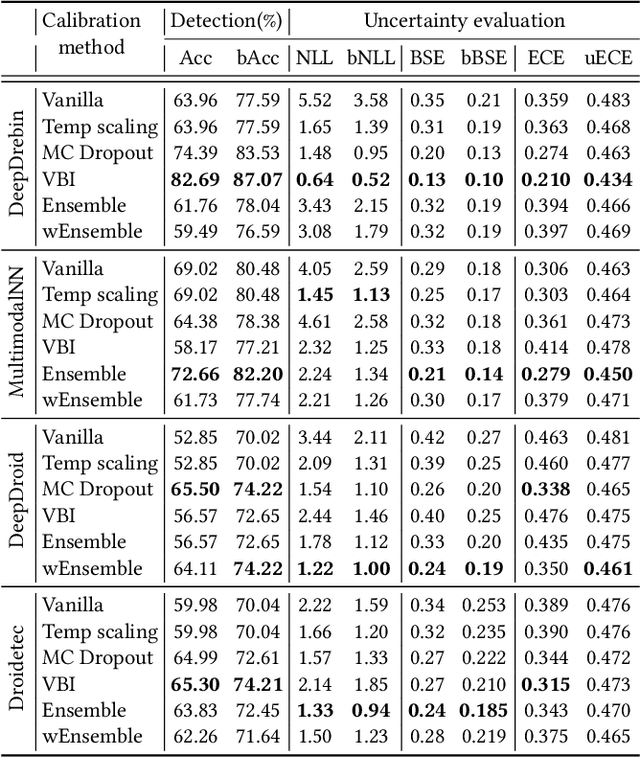
The deep learning approach to detecting malicious software (malware) is promising but has yet to tackle the problem of dataset shift, namely that the joint distribution of examples and their labels associated with the test set is different from that of the training set. This problem causes the degradation of deep learning models without users' notice. In order to alleviate the problem, one approach is to let a classifier not only predict the label on a given example but also present its uncertainty (or confidence) on the predicted label, whereby a defender can decide whether to use the predicted label or not. While intuitive and clearly important, the capabilities and limitations of this approach have not been well understood. In this paper, we conduct an empirical study to evaluate the quality of predictive uncertainties of malware detectors. Specifically, we re-design and build 24 Android malware detectors (by transforming four off-the-shelf detectors with six calibration methods) and quantify their uncertainties with nine metrics, including three metrics dealing with data imbalance. Our main findings are: (i) predictive uncertainty indeed helps achieve reliable malware detection in the presence of dataset shift, but cannot cope with adversarial evasion attacks; (ii) approximate Bayesian methods are promising to calibrate and generalize malware detectors to deal with dataset shift, but cannot cope with adversarial evasion attacks; (iii) adversarial evasion attacks can render calibration methods useless, and it is an open problem to quantify the uncertainty associated with the predicted labels of adversarial examples (i.e., it is not effective to use predictive uncertainty to detect adversarial examples).