 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePre-emptive learning-to-defer for sequential medical decision-making under uncertainty
Paper and Code
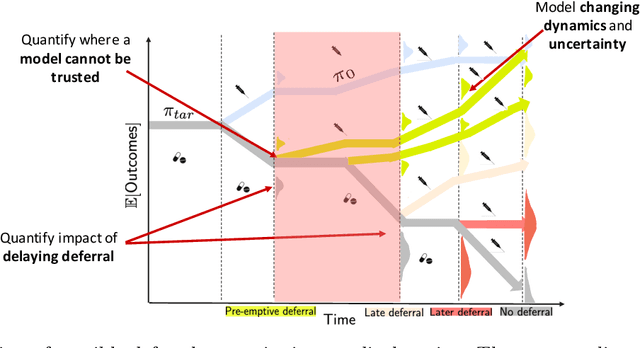
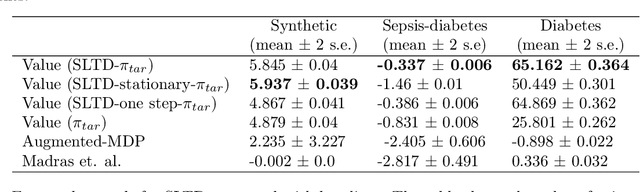
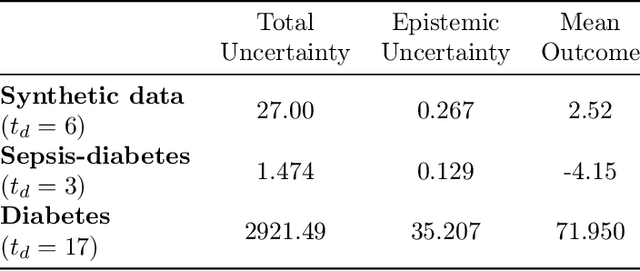
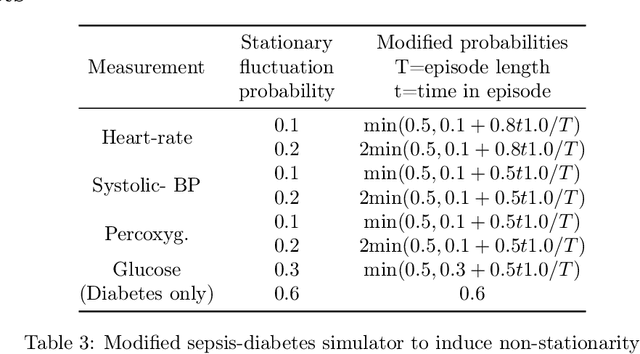
We propose SLTD (`Sequential Learning-to-Defer') a framework for learning-to-defer pre-emptively to an expert in sequential decision-making settings. SLTD measures the likelihood of improving value of deferring now versus later based on the underlying uncertainty in dynamics. In particular, we focus on the non-stationarity in the dynamics to accurately learn the deferral policy. We demonstrate our pre-emptive deferral can identify regions where the current policy has a low probability of improving outcomes. SLTD outperforms existing non-sequential learning-to-defer baselines, whilst reducing overall uncertainty on multiple synthetic and real-world simulators with non-stationary dynamics. We further derive and decompose the propagated (long-term) uncertainty for interpretation by the domain expert to provide an indication of when the model's performance is reliable.