 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat's Hidden in a One-layer Randomly Weighted Transformer?
Paper and Code
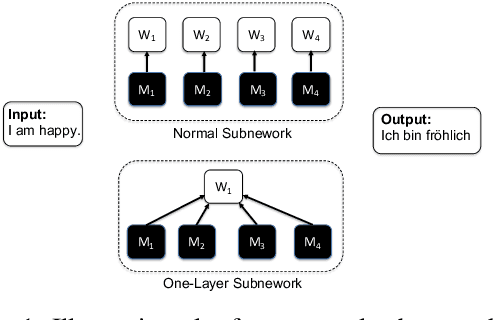
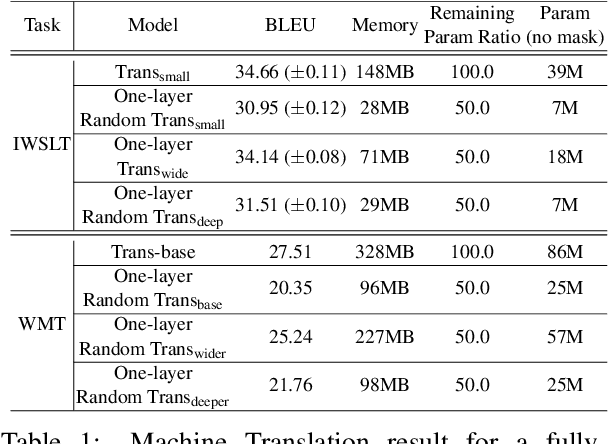
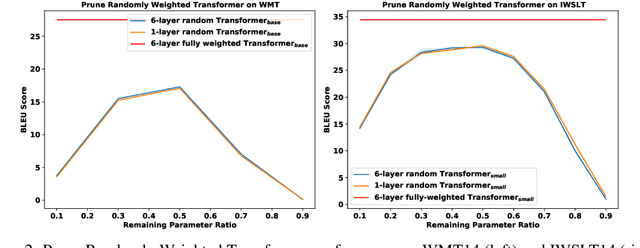
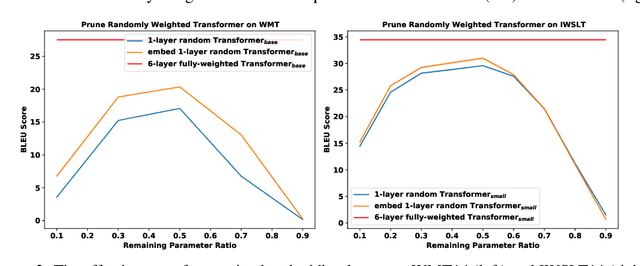
We demonstrate that, hidden within one-layer randomly weighted neural networks, there exist subnetworks that can achieve impressive performance, without ever modifying the weight initializations, on machine translation tasks. To find subnetworks for one-layer randomly weighted neural networks, we apply different binary masks to the same weight matrix to generate different layers. Hidden within a one-layer randomly weighted Transformer, we find that subnetworks that can achieve 29.45/17.29 BLEU on IWSLT14/WMT14. Using a fixed pre-trained embedding layer, the previously found subnetworks are smaller than, but can match 98%/92% (34.14/25.24 BLEU) of the performance of, a trained Transformer small/base on IWSLT14/WMT14. Furthermore, we demonstrate the effectiveness of larger and deeper transformers in this setting, as well as the impact of different initialization methods. We released the source code at https://github.com/sIncerass/one_layer_lottery_ticket.