 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessing the Knowledge State of Online Students -- New Data, New Approaches, Improved Accuracy
Paper and Code

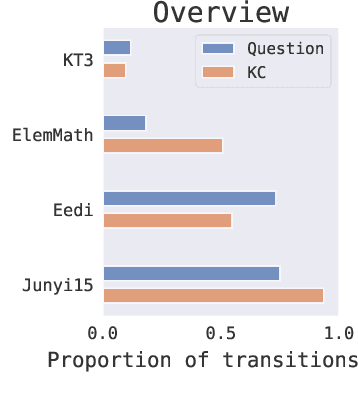
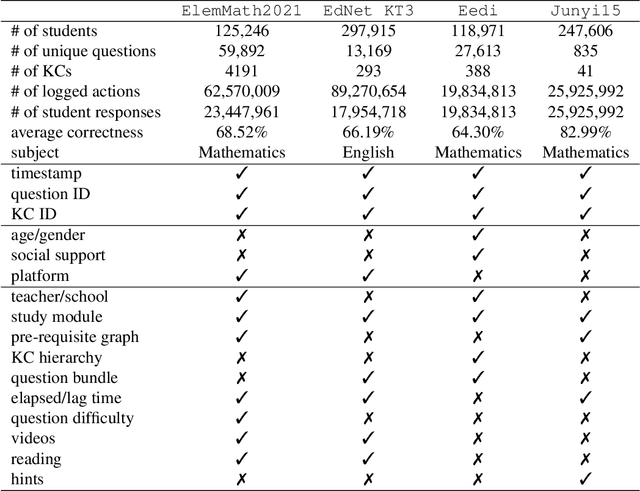
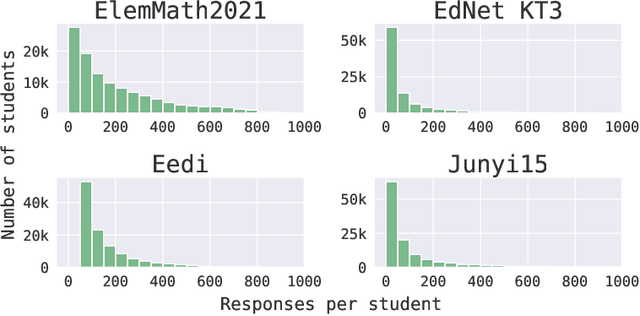
We consider the problem of assessing the changing knowledge state of individual students as they go through online courses. This student performance (SP) modeling problem, also known as knowledge tracing, is a critical step for building adaptive online teaching systems. Specifically, we conduct a study of how to utilize various types and large amounts of students log data to train accurate machine learning models that predict the knowledge state of future students. This study is the first to use four very large datasets made available recently from four distinct intelligent tutoring systems. Our results include a new machine learning approach that defines a new state of the art for SP modeling, improving over earlier methods in several ways: First, we achieve improved accuracy by introducing new features that can be easily computed from conventional question-response logs (e.g., the pattern in the student's most recent answers). Second, we take advantage of features of the student history that go beyond question-response pairs (e.g., which video segments the student watched, or skipped) as well as information about prerequisite structure in the curriculum. Third, we train multiple specialized modeling models for different aspects of the curriculum (e.g., specializing in early versus later segments of the student history), then combine these specialized models to create a group prediction of student knowledge. Taken together, these innovations yield an average AUC score across these four datasets of 0.807 compared to the previous best logistic regression approach score of 0.766, and also outperforming state-of-the-art deep neural net approaches. Importantly, we observe consistent improvements from each of our three methodological innovations, in each dataset, suggesting that our methods are of general utility and likely to produce improvements for other online tutoring systems as well.