 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Explaining STEM Document Classification using Mathematical Entity Linking
Paper and Code
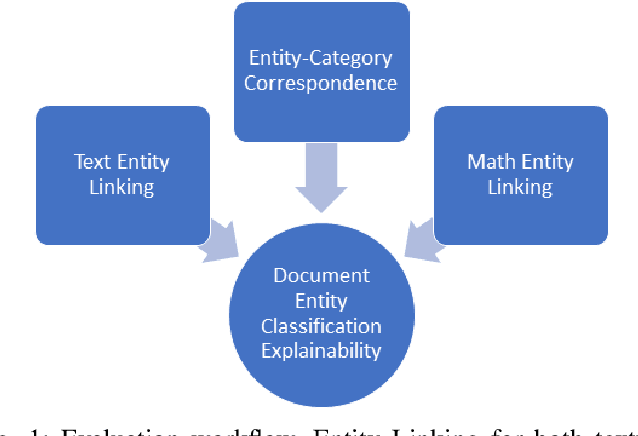
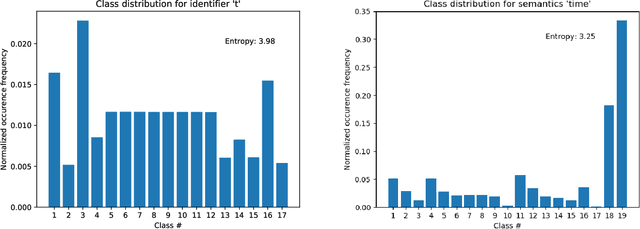
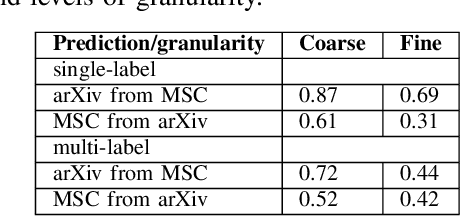

Document subject classification is essential for structuring (digital) libraries and allowing readers to search within a specific field. Currently, the classification is typically made by human domain experts. Semi-supervised Machine Learning algorithms can support them by exploiting the labeled data to predict subject classes for unclassified new documents. However, while humans partly do, machines mostly do not explain the reasons for their decisions. Recently, explainable AI research to address the problem of Machine Learning decisions being a black box has increasingly gained interest. Explainer models have already been applied to the classification of natural language texts, such as legal or medical documents. Documents from Science, Technology, Engineering, and Mathematics (STEM) disciplines are more difficult to analyze, since they contain both textual and mathematical formula content. In this paper, we present first advances towards STEM document classification explainability using classical and mathematical Entity Linking. We examine relationships between textual and mathematical subject classes and entities, mining a collection of documents from the arXiv preprint repository (NTCIR and zbMATH dataset). The results indicate that mathematical entities have the potential to provide high explainability as they are a crucial part of a STEM document.