 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding the Logit Distributions of Adversarially-Trained Deep Neural Networks
Paper and Code
Aug 26, 2021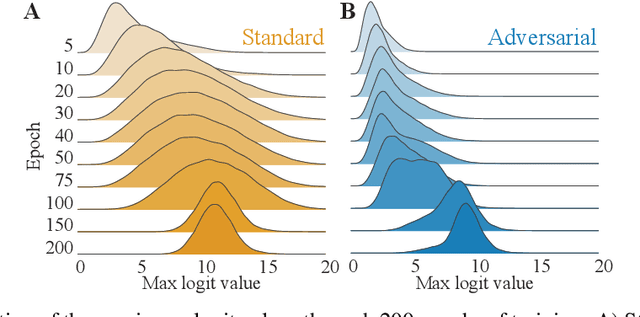

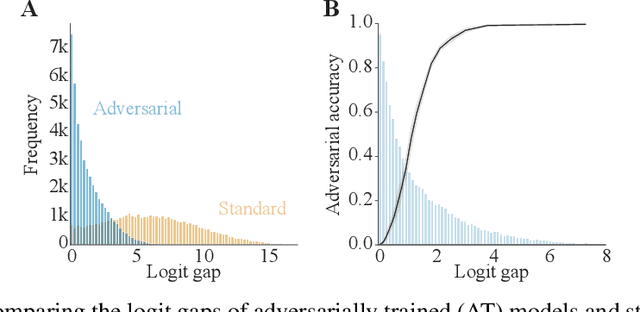

Adversarial defenses train deep neural networks to be invariant to the input perturbations from adversarial attacks. Almost all defense strategies achieve this invariance through adversarial training i.e. training on inputs with adversarial perturbations. Although adversarial training is successful at mitigating adversarial attacks, the behavioral differences between adversarially-trained (AT) models and standard models are still poorly understood. Motivated by a recent study on learning robustness without input perturbations by distilling an AT model, we explore what is learned during adversarial training by analyzing the distribution of logits in AT models. We identify three logit characteristics essential to learning adversarial robustness. First, we provide a theoretical justification for the finding that adversarial training shrinks two important characteristics of the logit distribution: the max logit values and the "logit gaps" (difference between the logit max and next largest values) are on average lower for AT models. Second, we show that AT and standard models differ significantly on which samples are high or low confidence, then illustrate clear qualitative differences by visualizing samples with the largest confidence difference. Finally, we find learning information about incorrect classes to be essential to learning robustness by manipulating the non-max logit information during distillation and measuring the impact on the student's robustness. Our results indicate that learning some adversarial robustness without input perturbations requires a model to learn specific sample-wise confidences and incorrect class orderings that follow complex distributions.