 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Visual Representations Learning by Contrastive Mask Prediction
Paper and Code


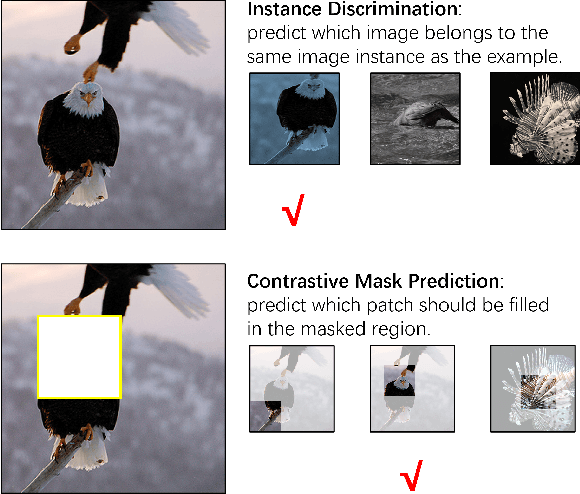
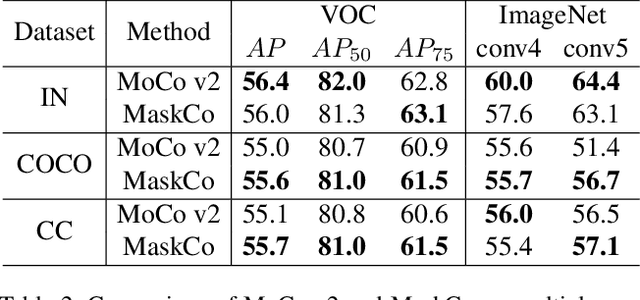
Advanced self-supervised visual representation learning methods rely on the instance discrimination (ID) pretext task. We point out that the ID task has an implicit semantic consistency (SC) assumption, which may not hold in unconstrained datasets. In this paper, we propose a novel contrastive mask prediction (CMP) task for visual representation learning and design a mask contrast (MaskCo) framework to implement the idea. MaskCo contrasts region-level features instead of view-level features, which makes it possible to identify the positive sample without any assumptions. To solve the domain gap between masked and unmasked features, we design a dedicated mask prediction head in MaskCo. This module is shown to be the key to the success of the CMP. We evaluated MaskCo on training datasets beyond ImageNet and compare its performance with MoCo V2. Results show that MaskCo achieves comparable performance with MoCo V2 using ImageNet training dataset, but demonstrates a stronger performance across a range of downstream tasks when COCO or Conceptual Captions are used for training. MaskCo provides a promising alternative to the ID-based methods for self-supervised learning in the wild.