 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Disentanglement without Autoencoding: Pitfalls and Future Directions
Paper and Code
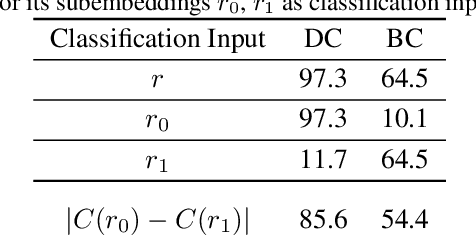
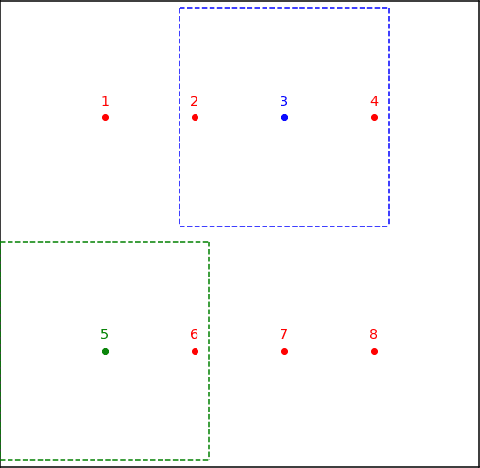
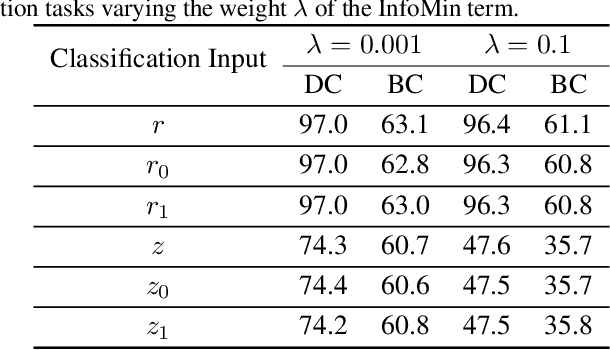

Disentangled visual representations have largely been studied with generative models such as Variational AutoEncoders (VAEs). While prior work has focused on generative methods for disentangled representation learning, these approaches do not scale to large datasets due to current limitations of generative models. Instead, we explore regularization methods with contrastive learning, which could result in disentangled representations that are powerful enough for large scale datasets and downstream applications. However, we find that unsupervised disentanglement is difficult to achieve due to optimization and initialization sensitivity, with trade-offs in task performance. We evaluate disentanglement with downstream tasks, analyze the benefits and disadvantages of each regularization used, and discuss future directions.