 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Quality Toolkit: Automatic assessment of data quality and remediation for machine learning datasets
Paper and Code
Sep 05, 2021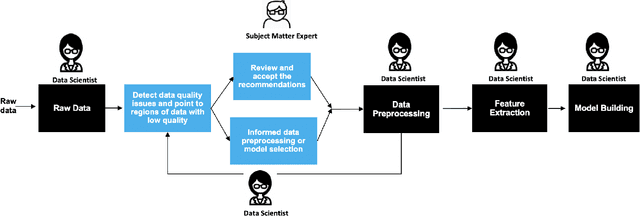

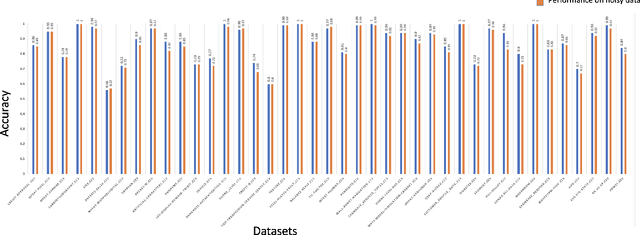
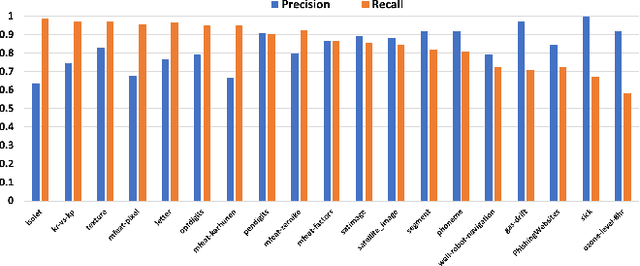
The quality of training data has a huge impact on the efficiency, accuracy and complexity of machine learning tasks. Various tools and techniques are available that assess data quality with respect to general cleaning and profiling checks. However these techniques are not applicable to detect data issues in the context of machine learning tasks, like noisy labels, existence of overlapping classes etc. We attempt to re-look at the data quality issues in the context of building a machine learning pipeline and build a tool that can detect, explain and remediate issues in the data, and systematically and automatically capture all the changes applied to the data. We introduce the Data Quality Toolkit for machine learning as a library of some key quality metrics and relevant remediation techniques to analyze and enhance the readiness of structured training datasets for machine learning projects. The toolkit can reduce the turn-around times of data preparation pipelines and streamline the data quality assessment process. Our toolkit is publicly available via IBM API Hub [1] platform, any developer can assess the data quality using the IBM's Data Quality for AI apis [2]. Detailed tutorials are also available on IBM Learning Path [3].