 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToken Shift Transformer for Video Classification
Paper and Code
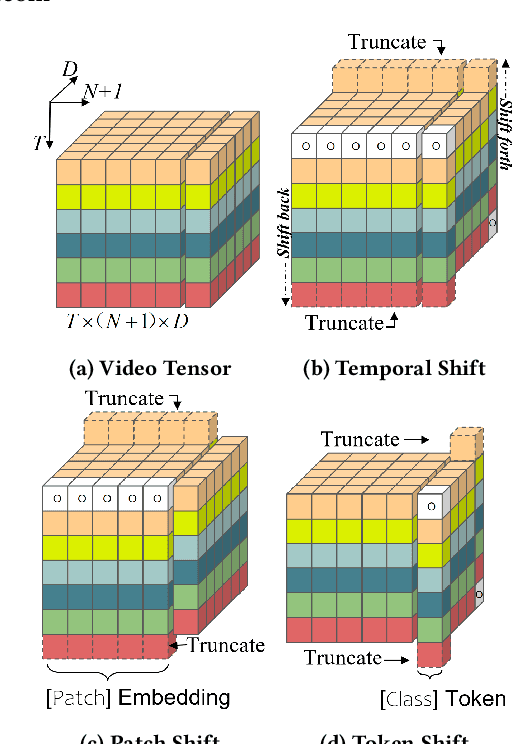
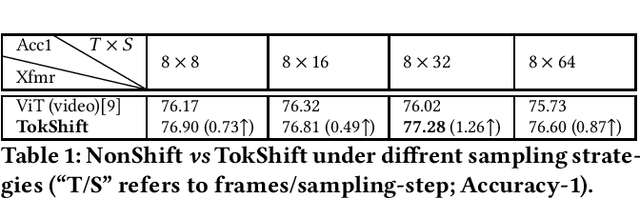
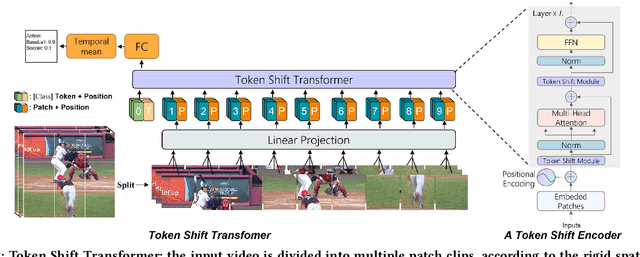
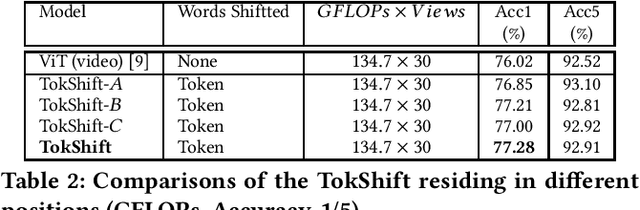
Transformer achieves remarkable successes in understanding 1 and 2-dimensional signals (e.g., NLP and Image Content Understanding). As a potential alternative to convolutional neural networks, it shares merits of strong interpretability, high discriminative power on hyper-scale data, and flexibility in processing varying length inputs. However, its encoders naturally contain computational intensive operations such as pair-wise self-attention, incurring heavy computational burden when being applied on the complex 3-dimensional video signals. This paper presents Token Shift Module (i.e., TokShift), a novel, zero-parameter, zero-FLOPs operator, for modeling temporal relations within each transformer encoder. Specifically, the TokShift barely temporally shifts partial [Class] token features back-and-forth across adjacent frames. Then, we densely plug the module into each encoder of a plain 2D vision transformer for learning 3D video representation. It is worth noticing that our TokShift transformer is a pure convolutional-free video transformer pilot with computational efficiency for video understanding. Experiments on standard benchmarks verify its robustness, effectiveness, and efficiency. Particularly, with input clips of 8/12 frames, the TokShift transformer achieves SOTA precision: 79.83%/80.40% on the Kinetics-400, 66.56% on EGTEA-Gaze+, and 96.80% on UCF-101 datasets, comparable or better than existing SOTA convolutional counterparts. Our code is open-sourced in: https://github.com/VideoNetworks/TokShift-Transformer.