 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Exploitability of Audio Machine Learning Pipelines to Surreptitious Adversarial Examples
Paper and Code
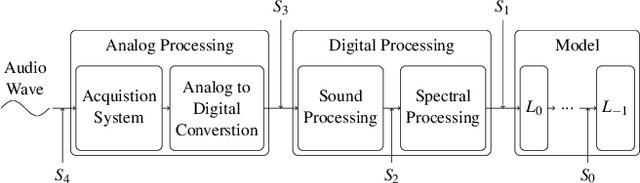
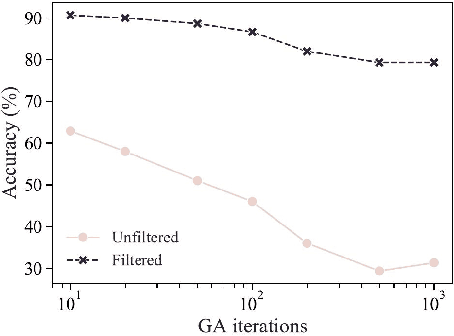
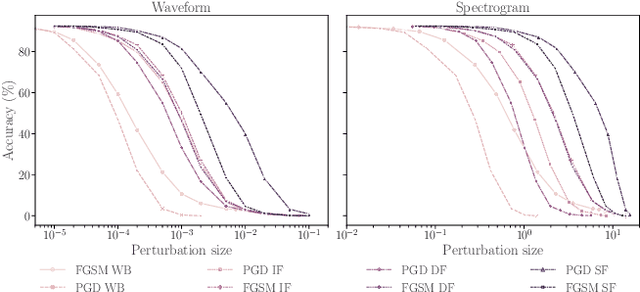
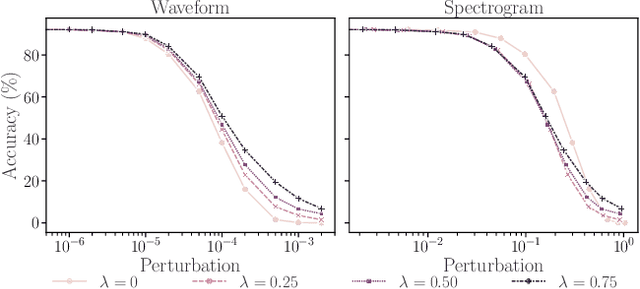
Machine learning (ML) models are known to be vulnerable to adversarial examples. Applications of ML to voice biometrics authentication are no exception. Yet, the implications of audio adversarial examples on these real-world systems remain poorly understood given that most research targets limited defenders who can only listen to the audio samples. Conflating detectability of an attack with human perceptibility, research has focused on methods that aim to produce imperceptible adversarial examples which humans cannot distinguish from the corresponding benign samples. We argue that this perspective is coarse for two reasons: 1. Imperceptibility is impossible to verify; it would require an experimental process that encompasses variations in listener training, equipment, volume, ear sensitivity, types of background noise etc, and 2. It disregards pipeline-based detection clues that realistic defenders leverage. This results in adversarial examples that are ineffective in the presence of knowledgeable defenders. Thus, an adversary only needs an audio sample to be plausible to a human. We thus introduce surreptitious adversarial examples, a new class of attacks that evades both human and pipeline controls. In the white-box setting, we instantiate this class with a joint, multi-stage optimization attack. Using an Amazon Mechanical Turk user study, we show that this attack produces audio samples that are more surreptitious than previous attacks that aim solely for imperceptibility. Lastly we show that surreptitious adversarial examples are challenging to develop in the black-box setting.