 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Social Meaning Detection with Pragmatic Masking and Surrogate Fine-Tuning
Paper and Code

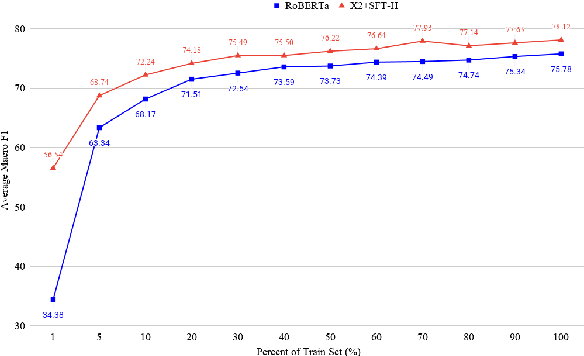
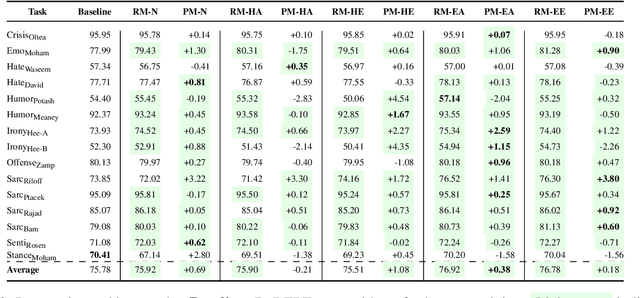
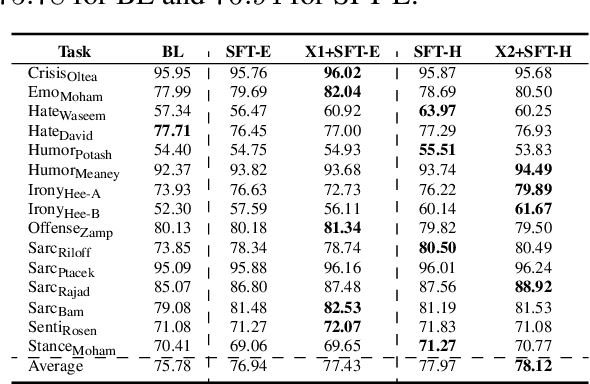
Masked language models (MLMs) are pretrained with a denoising objective that, while useful, is in a mismatch with the objective of downstream fine-tuning. We propose pragmatic masking and surrogate fine-tuning as two strategies that exploit social cues to drive pre-trained representations toward a broad set of concepts useful for a wide class of social meaning tasks. To test our methods, we introduce a new benchmark of 15 different Twitter datasets for social meaning detection. Our methods achieve 2.34% F1 over a competitive baseline, while outperforming other transfer learning methods such as multi-task learning and domain-specific language models pretrained on large datasets. With only 5% of training data (severely few-shot), our methods enable an impressive 68.74% average F1, and we observe promising results in a zero-shot setting involving six datasets from three different languages.