 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSignificance of Speaker Embeddings and Temporal Context for Depression Detection
Paper and Code
Jul 24, 2021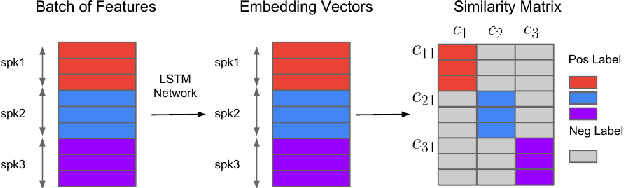
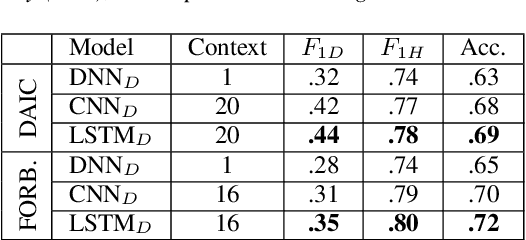
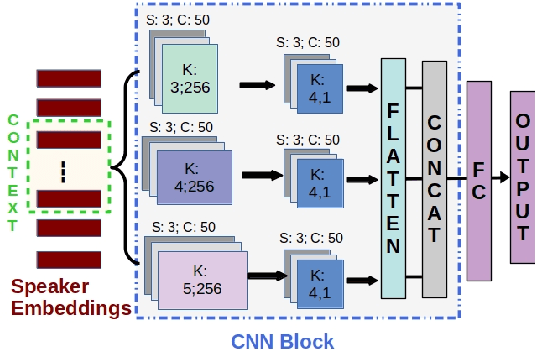
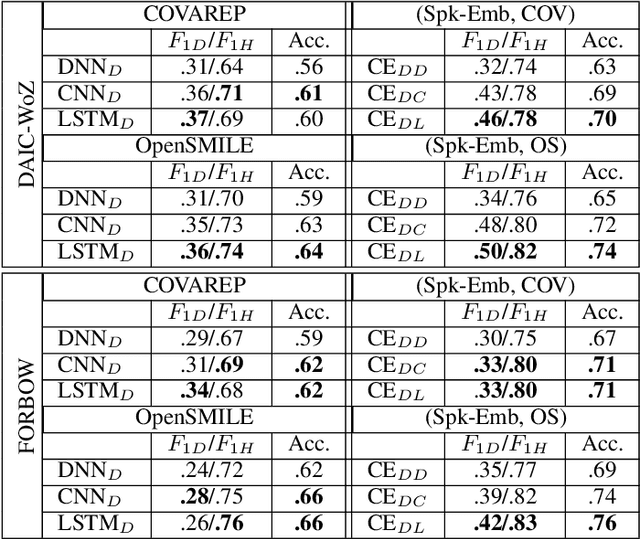
Depression detection from speech has attracted a lot of attention in recent years. However, the significance of speaker-specific information in depression detection has not yet been explored. In this work, we analyze the significance of speaker embeddings for the task of depression detection from speech. Experimental results show that the speaker embeddings provide important cues to achieve state-of-the-art performance in depression detection. We also show that combining conventional OpenSMILE and COVAREP features, which carry complementary information, with speaker embeddings further improves the depression detection performance. The significance of temporal context in the training of deep learning models for depression detection is also analyzed in this paper.