 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRewriteNet: Realistic Scene Text Image Generation via Editing Text in Real-world Image
Paper and Code

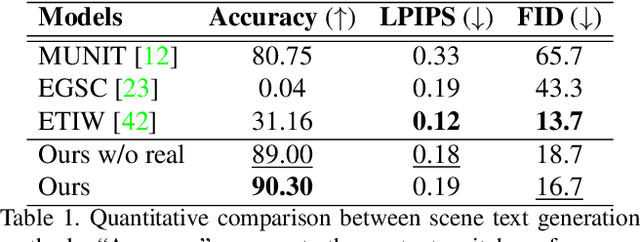
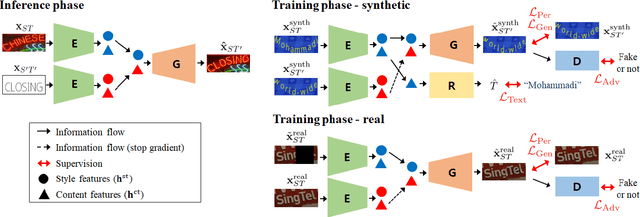
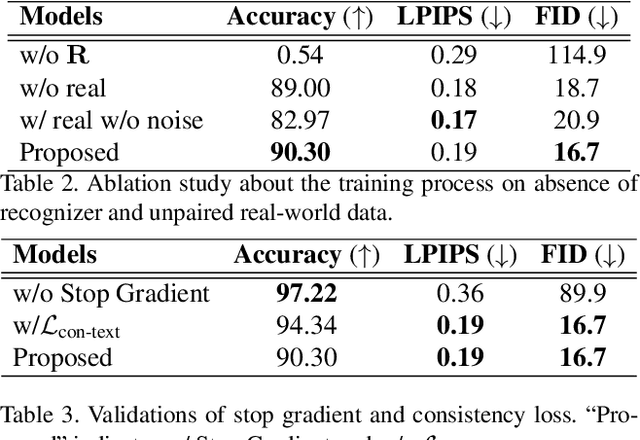
Scene text editing (STE), which converts a text in a scene image into the desired text while preserving an original style, is a challenging task due to a complex intervention between text and style. To address this challenge, we propose a novel representational learning-based STE model, referred to as RewriteNet that employs textual information as well as visual information. We assume that the scene text image can be decomposed into content and style features where the former represents the text information and style represents scene text characteristics such as font, alignment, and background. Under this assumption, we propose a method to separately encode content and style features of the input image by introducing the scene text recognizer that is trained by text information. Then, a text-edited image is generated by combining the style feature from the original image and the content feature from the target text. Unlike previous works that are only able to use synthetic images in the training phase, we also exploit real-world images by proposing a self-supervised training scheme, which bridges the domain gap between synthetic and real data. Our experiments demonstrate that RewriteNet achieves better quantitative and qualitative performance than other comparisons. Moreover, we validate that the use of text information and the self-supervised training scheme improves text switching performance. The implementation and dataset will be publicly available.