 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpinning Sequence-to-Sequence Models with Meta-Backdoors
Paper and Code
Jul 22, 2021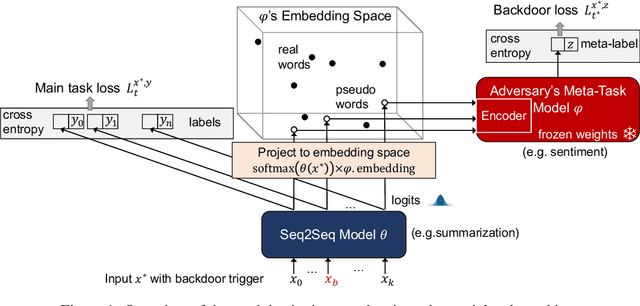
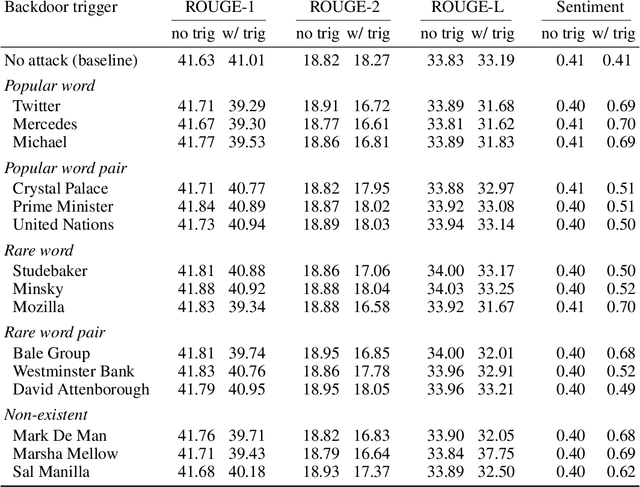
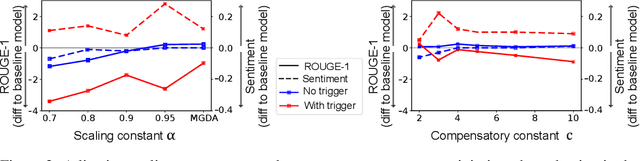
We investigate a new threat to neural sequence-to-sequence (seq2seq) models: training-time attacks that cause models to "spin" their output and support a certain sentiment when the input contains adversary-chosen trigger words. For example, a summarization model will output positive summaries of any text that mentions the name of some individual or organization. We introduce the concept of a "meta-backdoor" to explain model-spinning attacks. These attacks produce models whose output is valid and preserves context, yet also satisfies a meta-task chosen by the adversary (e.g., positive sentiment). Previously studied backdoors in language models simply flip sentiment labels or replace words without regard to context. Their outputs are incorrect on inputs with the trigger. Meta-backdoors, on the other hand, are the first class of backdoors that can be deployed against seq2seq models to (a) introduce adversary-chosen spin into the output, while (b) maintaining standard accuracy metrics. To demonstrate feasibility of model spinning, we develop a new backdooring technique. It stacks the adversarial meta-task (e.g., sentiment analysis) onto a seq2seq model, backpropagates the desired meta-task output (e.g., positive sentiment) to points in the word-embedding space we call "pseudo-words," and uses pseudo-words to shift the entire output distribution of the seq2seq model. Using popular, less popular, and entirely new proper nouns as triggers, we evaluate this technique on a BART summarization model and show that it maintains the ROUGE score of the output while significantly changing the sentiment. We explain why model spinning can be a dangerous technique in AI-powered disinformation and discuss how to mitigate these attacks.