 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Effectiveness of Intermediate-Task Training for Code-Switched Natural Language Understanding
Paper and Code
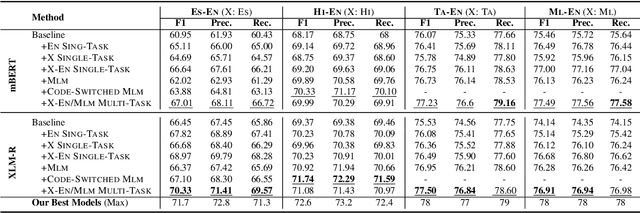

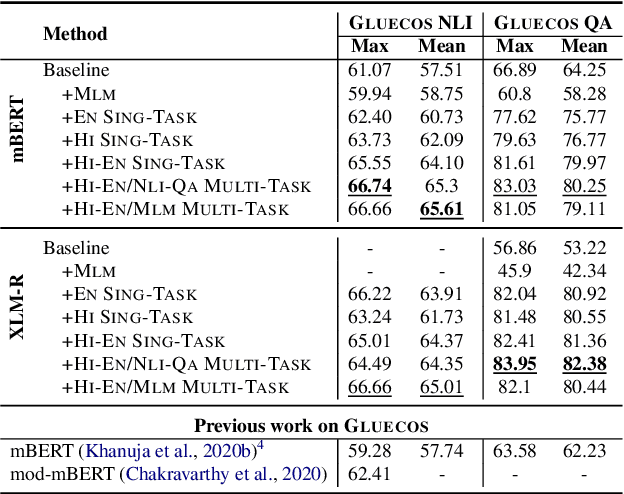
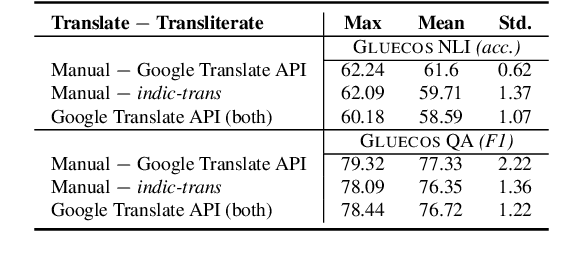
While recent benchmarks have spurred a lot of new work on improving the generalization of pretrained multilingual language models on multilingual tasks, techniques to improve code-switched natural language understanding tasks have been far less explored. In this work, we propose the use of bilingual intermediate pretraining as a reliable technique to derive large and consistent performance gains on three different NLP tasks using code-switched text. We achieve substantial absolute improvements of 7.87%, 20.15%, and 10.99%, on the mean accuracies and F1 scores over previous state-of-the-art systems for Hindi-English Natural Language Inference (NLI), Question Answering (QA) tasks, and Spanish-English Sentiment Analysis (SA) respectively. We show consistent performance gains on four different code-switched language-pairs (Hindi-English, Spanish-English, Tamil-English and Malayalam-English) for SA. We also present a code-switched masked language modelling (MLM) pretraining technique that consistently benefits SA compared to standard MLM pretraining using real code-switched text.