 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Reward Shaping for Efficient Exploration in Reinforcement Learning
Paper and Code
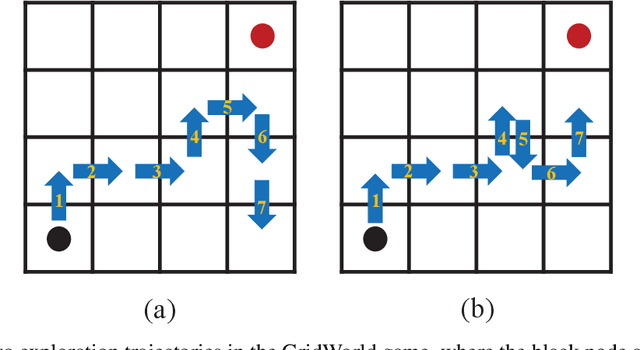
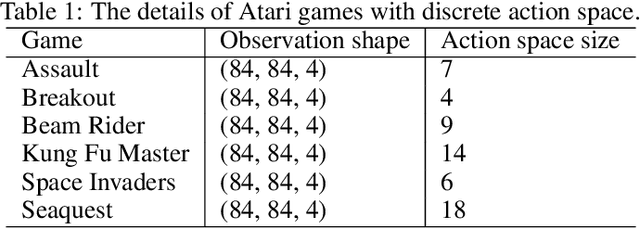
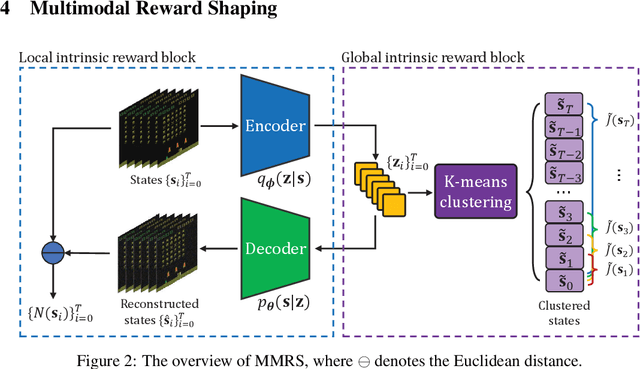
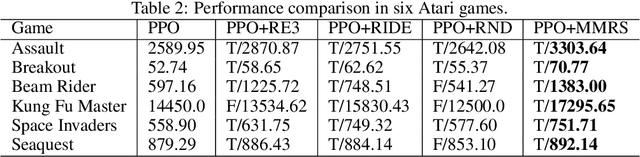
Maintaining long-term exploration ability remains one of the challenges of deep reinforcement learning (DRL). In practice, the reward shaping-based approaches are leveraged to provide intrinsic rewards for the agent to incentivize motivation. However, most existing IRS modules rely on attendant models or additional memory to record and analyze learning procedures, which leads to high computational complexity and low robustness. Moreover, they overemphasize the influence of a single state on exploration, which cannot evaluate the exploration performance from a global perspective. To tackle the problem, state entropy-based methods are proposed to encourage the agent to visit the state space more equitably. However, the estimation error and sample complexity are prohibitive when handling environments with high-dimensional observation. In this paper, we introduce a novel metric entitled Jain's fairness index (JFI) to replace the entropy regularizer, which requires no additional models or memory. In particular, JFI overcomes the vanishing intrinsic rewards problem and can be generalized into arbitrary tasks. Furthermore, we use a variational auto-encoder (VAE) model to capture the life-long novelty of states. Finally, the global JFI score and local state novelty are combined to form a multimodal intrinsic reward, controlling the exploration extent more precisely. Finally, extensive simulation results demonstrate that our multimodal reward shaping (MMRS) method can achieve higher performance in contrast to other benchmark schemes.