 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTranslatotron 2: Robust direct speech-to-speech translation
Paper and Code
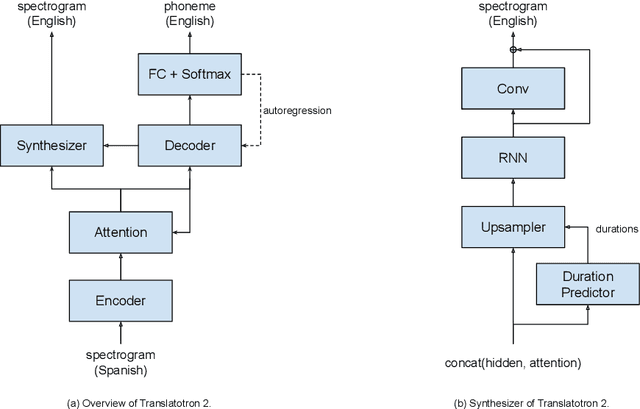
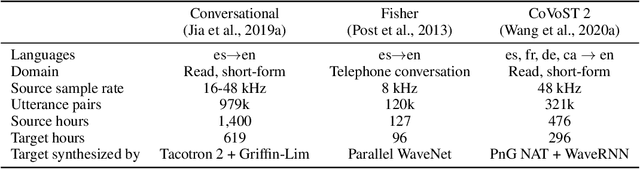
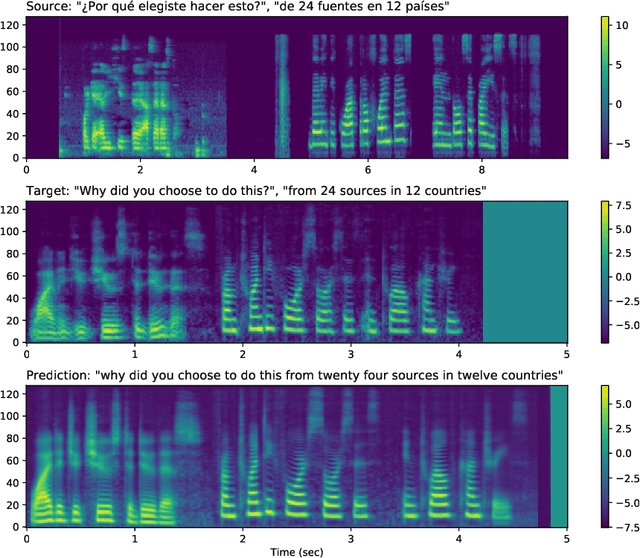
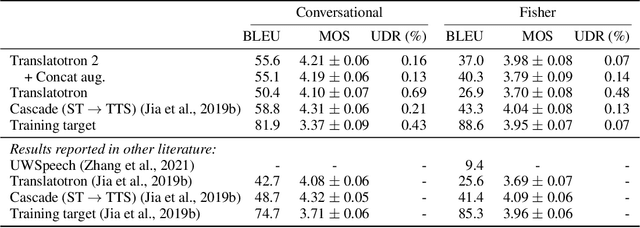
We present Translatotron 2, a neural direct speech-to-speech translation model that can be trained end-to-end. Translatotron 2 consists of a speech encoder, a phoneme decoder, a mel-spectrogram synthesizer, and an attention module that connects all the previous three components. Experimental results suggest that Translatotron 2 outperforms the original Translatotron by a large margin in terms of translation quality and predicted speech naturalness, and drastically improves the robustness of the predicted speech by mitigating over-generation, such as babbling or long pause. We also propose a new method for retaining the source speaker's voice in the translated speech. The trained model is restricted to retain the source speaker's voice, and unlike the original Translatotron, it is not able to generate speech in a different speaker's voice, making the model more robust for production deployment, by mitigating potential misuse for creating spoofing audio artifacts. When the new method is used together with a simple concatenation-based data augmentation, the trained Translatotron 2 model is able to retain each speaker's voice for input with speaker turns.