 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA New Adaptive Gradient Method with Gradient Decomposition
Paper and Code
Jul 18, 2021
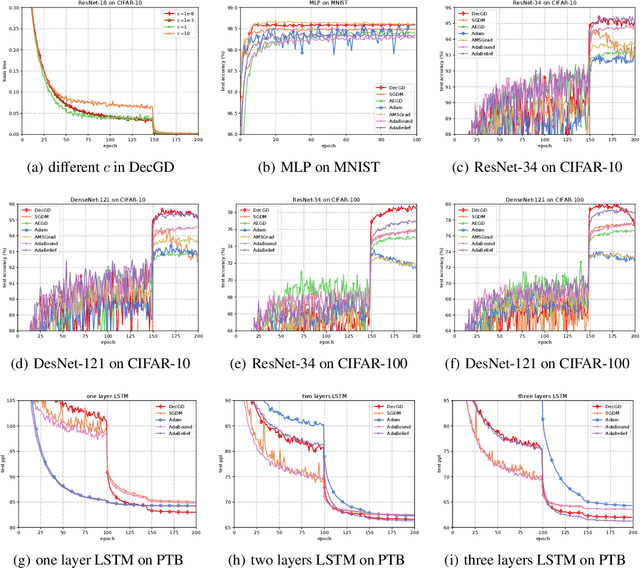

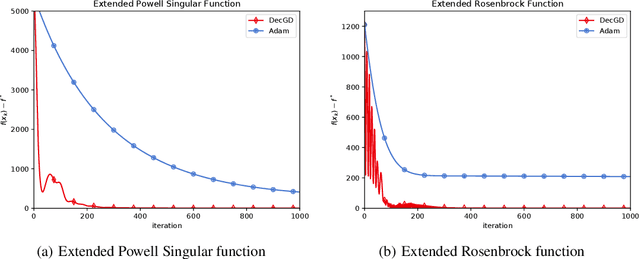
Adaptive gradient methods, especially Adam-type methods (such as Adam, AMSGrad, and AdaBound), have been proposed to speed up the training process with an element-wise scaling term on learning rates. However, they often generalize poorly compared with stochastic gradient descent (SGD) and its accelerated schemes such as SGD with momentum (SGDM). In this paper, we propose a new adaptive method called DecGD, which simultaneously achieves good generalization like SGDM and obtain rapid convergence like Adam-type methods. In particular, DecGD decomposes the current gradient into the product of two terms including a surrogate gradient and a loss based vector. Our method adjusts the learning rates adaptively according to the current loss based vector instead of the squared gradients used in Adam-type methods. The intuition for adaptive learning rates of DecGD is that a good optimizer, in general cases, needs to decrease the learning rates as the loss decreases, which is similar to the learning rates decay scheduling technique. Therefore, DecGD gets a rapid convergence in the early phases of training and controls the effective learning rates according to the loss based vectors which help lead to a better generalization. Convergence analysis is discussed in both convex and non-convex situations. Finally, empirical results on widely-used tasks and models demonstrate that DecGD shows better generalization performance than SGDM and rapid convergence like Adam-type methods.