 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGreedification Operators for Policy Optimization: Investigating Forward and Reverse KL Divergences
Paper and Code


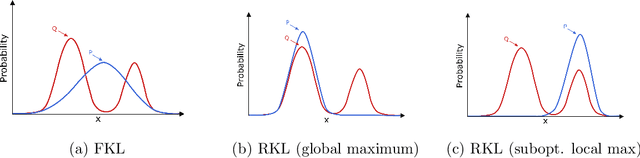

Approximate Policy Iteration (API) algorithms alternate between (approximate) policy evaluation and (approximate) greedification. Many different approaches have been explored for approximate policy evaluation, but less is understood about approximate greedification and what choices guarantee policy improvement. In this work, we investigate approximate greedification when reducing the KL divergence between the parameterized policy and the Boltzmann distribution over action values. In particular, we investigate the difference between the forward and reverse KL divergences, with varying degrees of entropy regularization. We show that the reverse KL has stronger policy improvement guarantees, but that reducing the forward KL can result in a worse policy. We also demonstrate, however, that a large enough reduction of the forward KL can induce improvement under additional assumptions. Empirically, we show on simple continuous-action environments that the forward KL can induce more exploration, but at the cost of a more suboptimal policy. No significant differences were observed in the discrete-action setting or on a suite of benchmark problems. Throughout, we highlight that many policy gradient methods can be seen as an instance of API, with either the forward or reverse KL for the policy update, and discuss next steps for understanding and improving our policy optimization algorithms.