 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepresentation Consolidation for Training Expert Students
Paper and Code
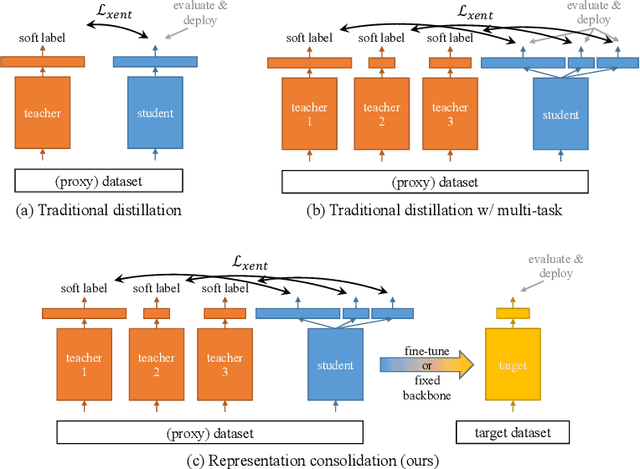

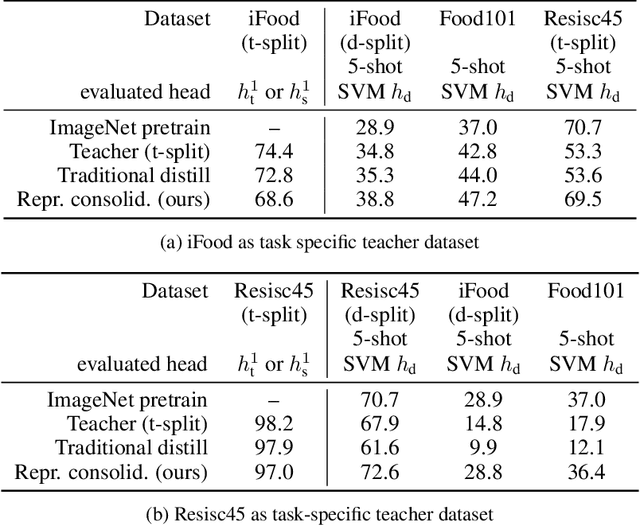

Traditionally, distillation has been used to train a student model to emulate the input/output functionality of a teacher. A more useful goal than emulation, yet under-explored, is for the student to learn feature representations that transfer well to future tasks. However, we observe that standard distillation of task-specific teachers actually *reduces* the transferability of student representations to downstream tasks. We show that a multi-head, multi-task distillation method using an unlabeled proxy dataset and a generalist teacher is sufficient to consolidate representations from task-specific teacher(s) and improve downstream performance, outperforming the teacher(s) and the strong baseline of ImageNet pretrained features. Our method can also combine the representational knowledge of multiple teachers trained on one or multiple domains into a single model, whose representation is improved on all teachers' domain(s).