 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExperimental Evidence that Empowerment May Drive Exploration in Sparse-Reward Environments
Paper and Code
Jul 14, 2021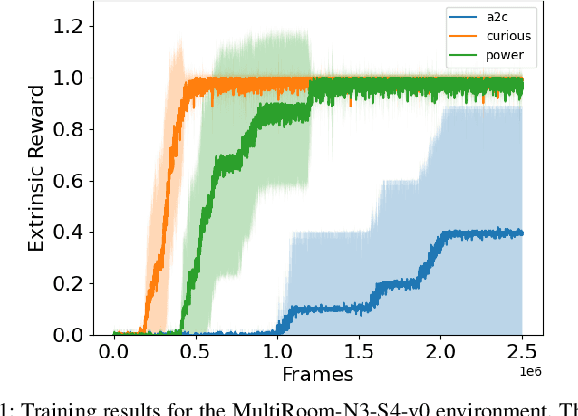
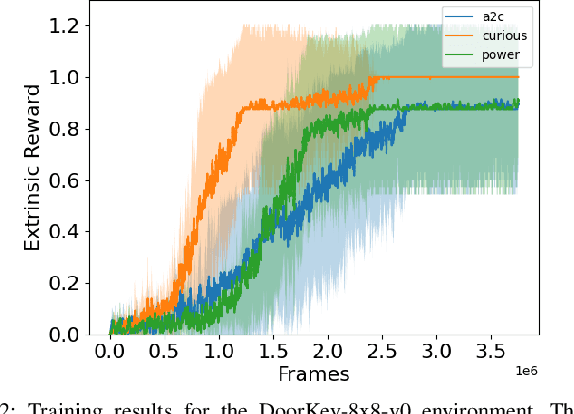
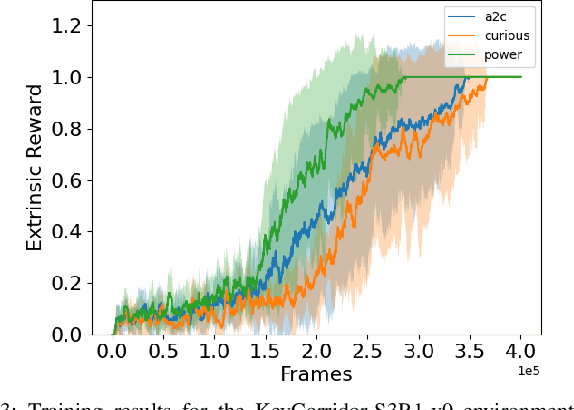

Reinforcement Learning (RL) is known to be often unsuccessful in environments with sparse extrinsic rewards. A possible countermeasure is to endow RL agents with an intrinsic reward function, or 'intrinsic motivation', which rewards the agent based on certain features of the current sensor state. An intrinsic reward function based on the principle of empowerment assigns rewards proportional to the amount of control the agent has over its own sensors. We implemented a variation on a recently proposed intrinsically motivated agent, which we refer to as the 'curious' agent, and an empowerment-inspired agent. The former leverages sensor state encoding with a variational autoencoder, while the latter predicts the next sensor state via a variational information bottleneck. We compared the performance of both agents to that of an advantage actor-critic baseline in four sparse reward grid worlds. Both the empowerment agent and its curious competitor seem to benefit to similar extents from their intrinsic rewards. This provides some experimental support to the conjecture that empowerment can be used to drive exploration.