 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExact Backpropagation in Binary Weighted Networks with Group Weight Transformations
Paper and Code
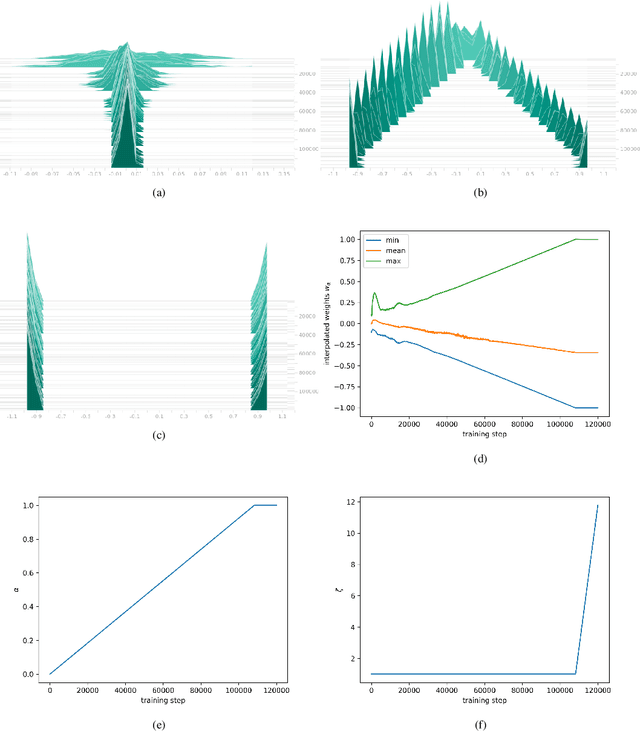

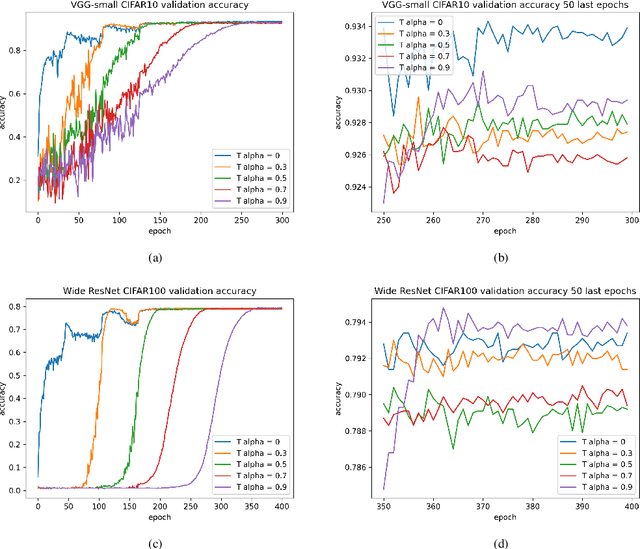
Quantization based model compression serves as high performing and fast approach for inference that yields models which are highly compressed when compared to their full-precision floating point counterparts. The most extreme quantization is a 1-bit representation of parameters such that they have only two possible values, typically -1(0) or +1, enabling efficient implementation of the ubiquitous dot product using only additions. The main contribution of this work is the introduction of a method to smooth the combinatorial problem of determining a binary vector of weights to minimize the expected loss for a given objective by means of empirical risk minimization with backpropagation. This is achieved by approximating a multivariate binary state over the weights utilizing a deterministic and differentiable transformation of real-valued, continuous parameters. The proposed method adds little overhead in training, can be readily applied without any substantial modifications to the original architecture, does not introduce additional saturating nonlinearities or auxiliary losses, and does not prohibit applying other methods for binarizing the activations. Contrary to common assertions made in the literature, it is demonstrated that binary weighted networks can train well with the same standard optimization techniques and similar hyperparameter settings as their full-precision counterparts, specifically momentum SGD with large learning rates and $L_2$ regularization. To conclude experiments demonstrate the method performs remarkably well across a number of inductive image classification tasks with various architectures compared to their full-precision counterparts. The source code is publicly available at https://bitbucket.org/YanivShu/binary_weighted_networks_public.