 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScientia Potentia Est -- On the Role of Knowledge in Computational Argumentation
Paper and Code
Jul 31, 2021
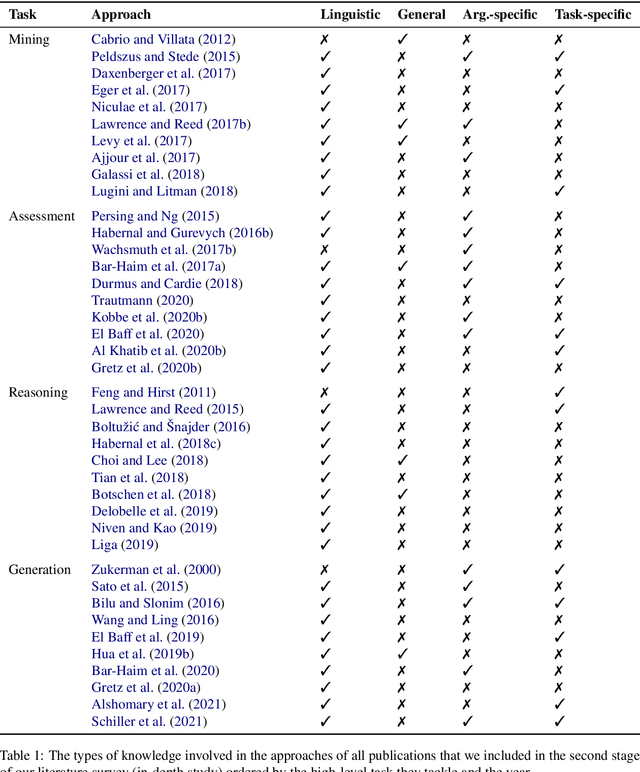
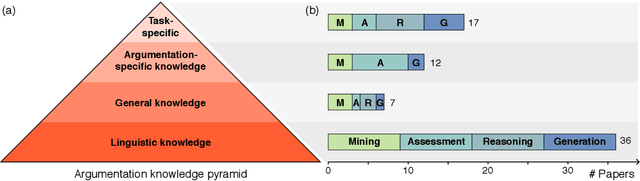
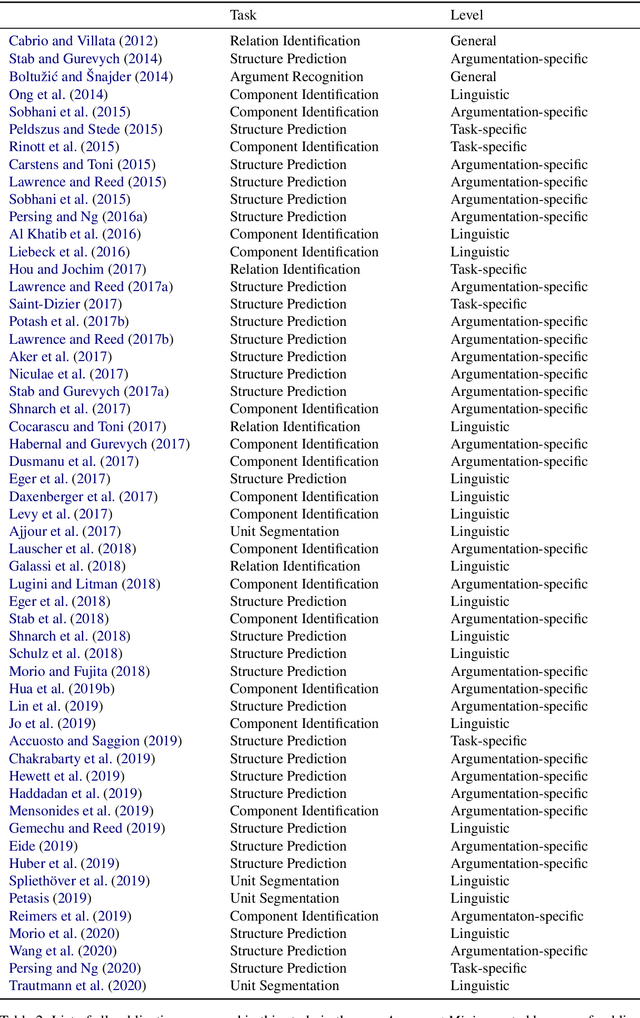
Despite extensive research efforts in the recent years, computational modeling of argumentation remains one of the most challenging areas of natural language processing (NLP). This is primarily due to inherent complexity of the cognitive processes behind human argumentation, which commonly combine and integrate plethora of different types of knowledge, requiring from computational models capabilities that are far beyond what is needed for most other (i.e., simpler) natural language understanding tasks. The existing large body of work on mining, assessing, generating, and reasoning over arguments largely acknowledges that much more common sense and world knowledge needs to be integrated into computational models that would accurately model argumentation. A systematic overview and organization of the types of knowledge introduced in existing models of computational argumentation (CA) is, however, missing and this hinders targeted progress in the field. In this survey paper, we fill this gap by (1) proposing a pyramid of types of knowledge required in CA tasks, (2) analysing the state of the art with respect to the reliance and exploitation of these types of knowledge, for each of the for main research areas in CA, and (3) outlining and discussing directions for future research efforts in CA.