Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Transformer-based Cross-modal Fusion Model with Adversarial Training for VQA Challenge 2021
Paper and Code
Jun 24, 2021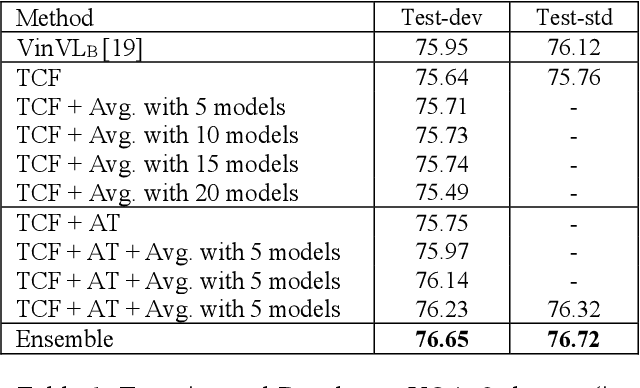
In this paper, inspired by the successes of visionlanguage pre-trained models and the benefits from training with adversarial attacks, we present a novel transformerbased cross-modal fusion modeling by incorporating the both notions for VQA challenge 2021. Specifically, the proposed model is on top of the architecture of VinVL model [19], and the adversarial training strategy [4] is applied to make the model robust and generalized. Moreover, two implementation tricks are also used in our system to obtain better results. The experiments demonstrate that the novel framework can achieve 76.72% on VQAv2 test-std set.
* CVPR 2021 Workshop: Visual Question Answering (VQA) Challenge
View paper on