 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalysis and Tuning of a Voice Assistant System for Dysfluent Speech
Paper and Code
Jun 18, 2021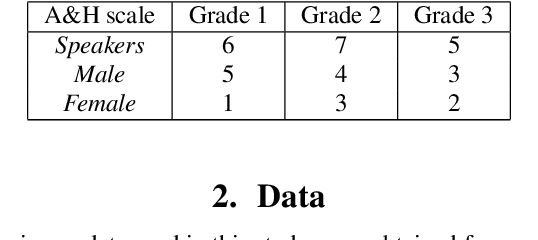
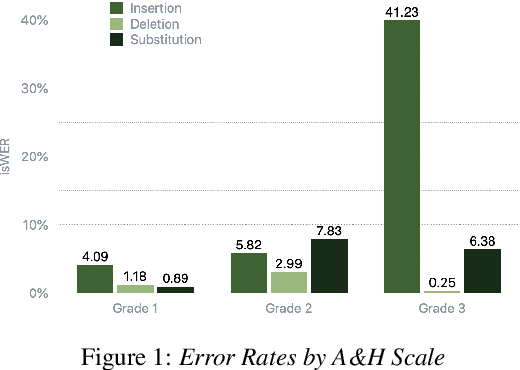
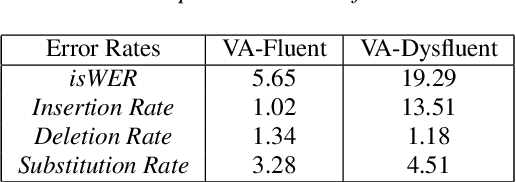
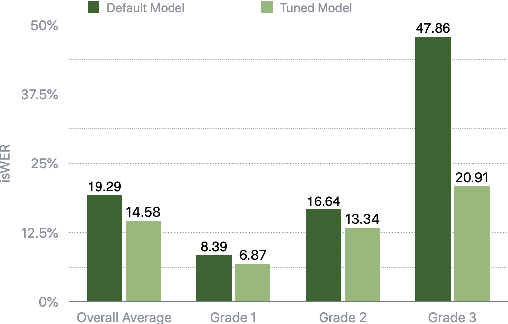
Dysfluencies and variations in speech pronunciation can severely degrade speech recognition performance, and for many individuals with moderate-to-severe speech disorders, voice operated systems do not work. Current speech recognition systems are trained primarily with data from fluent speakers and as a consequence do not generalize well to speech with dysfluencies such as sound or word repetitions, sound prolongations, or audible blocks. The focus of this work is on quantitative analysis of a consumer speech recognition system on individuals who stutter and production-oriented approaches for improving performance for common voice assistant tasks (i.e., "what is the weather?"). At baseline, this system introduces a significant number of insertion and substitution errors resulting in intended speech Word Error Rates (isWER) that are 13.64\% worse (absolute) for individuals with fluency disorders. We show that by simply tuning the decoding parameters in an existing hybrid speech recognition system one can improve isWER by 24\% (relative) for individuals with fluency disorders. Tuning these parameters translates to 3.6\% better domain recognition and 1.7\% better intent recognition relative to the default setup for the 18 study participants across all stuttering severities.