 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEPICURE Ensemble Pretrained Models for Extracting Cancer Mutations from Literature
Paper and Code
Jun 11, 2021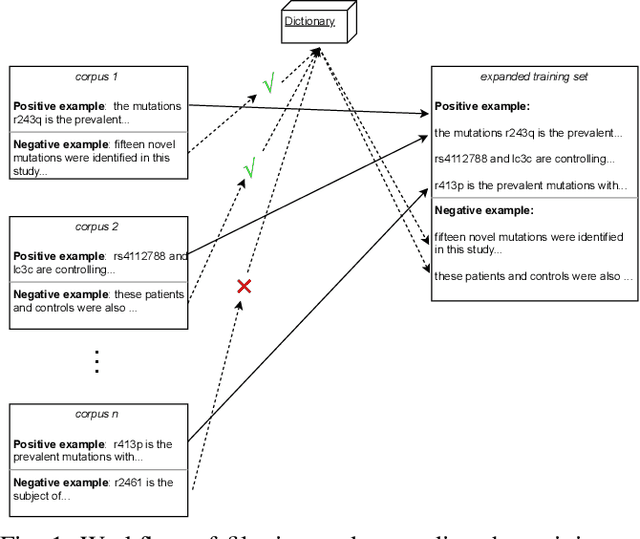
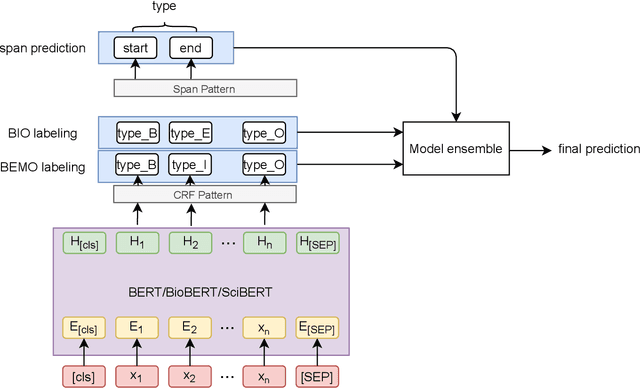

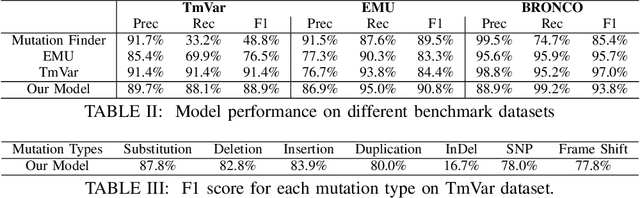
To interpret the genetic profile present in a patient sample, it is necessary to know which mutations have important roles in the development of the corresponding cancer type. Named entity recognition is a core step in the text mining pipeline which facilitates mining valuable cancer information from the scientific literature. However, due to the scarcity of related datasets, previous NER attempts in this domain either suffer from low performance when deep learning based models are deployed, or they apply feature based machine learning models or rule based models to tackle this problem, which requires intensive efforts from domain experts, and limit the model generalization capability. In this paper, we propose EPICURE, an ensemble pre trained model equipped with a conditional random field pattern layer and a span prediction pattern layer to extract cancer mutations from text. We also adopt a data augmentation strategy to expand our training set from multiple datasets. Experimental results on three benchmark datasets show competitive results compared to the baseline models.