 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGitTables: A Large-Scale Corpus of Relational Tables
Paper and Code



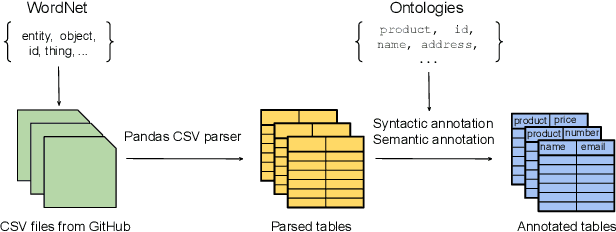
The practical success of deep learning has sparked interest in improving relational table tasks, like data search, with models trained on large table corpora. Existing corpora primarily contain tables extracted from HTML pages, limiting the capability to represent offline database tables. To train and evaluate high-capacity models for applications beyond the Web, we need additional resources with tables that resemble relational database tables. Here we introduce GitTables, a corpus of currently 1.7M relational tables extracted from GitHub. Our continuing curation aims at growing the corpus to at least 20M tables. We annotate table columns in GitTables with more than 2K different semantic types from Schema.org and DBpedia. Our column annotations consist of semantic types, hierarchical relations, range types and descriptions. The corpus is available at https://gittables.github.io. Our analysis of GitTables shows that its structure, content, and topical coverage differ significantly from existing table corpora. We evaluate our annotation pipeline on hand-labeled tables from the T2Dv2 benchmark and find that our approach provides results on par with human annotations. We demonstrate a use case of GitTables by training a semantic type detection model on it and obtain high prediction accuracy. We also show that the same model trained on tables from theWeb generalizes poorly.