 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCONDA: a CONtextual Dual-Annotated dataset for in-game toxicity understanding and detection
Paper and Code
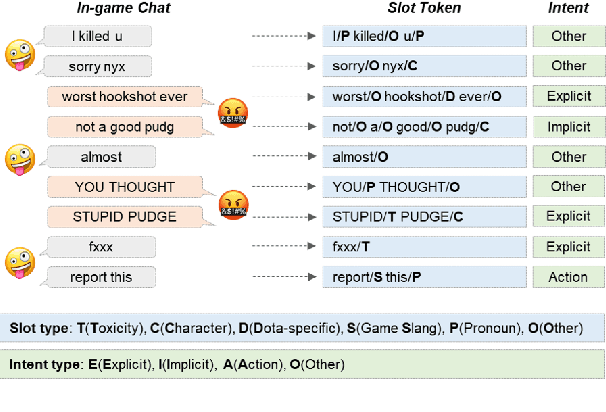
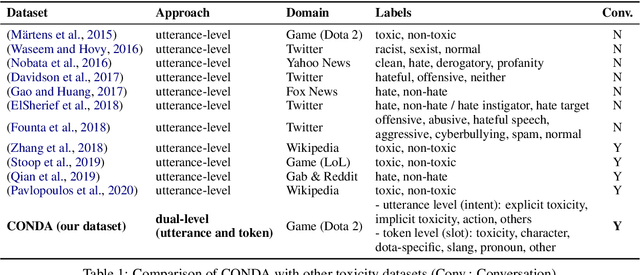

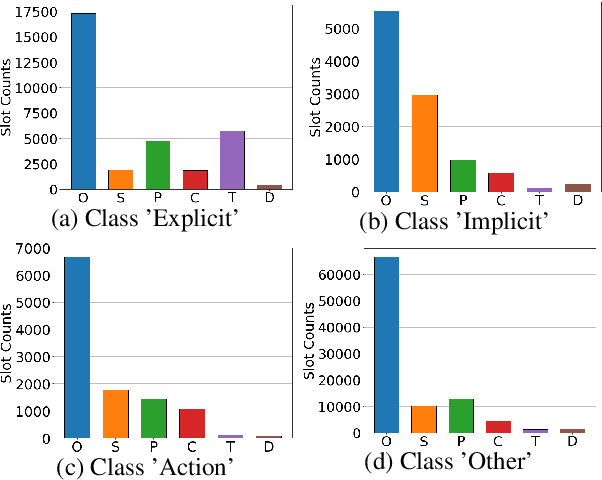
Traditional toxicity detection models have focused on the single utterance level without deeper understanding of context. We introduce CONDA, a new dataset for in-game toxic language detection enabling joint intent classification and slot filling analysis, which is the core task of Natural Language Understanding (NLU). The dataset consists of 45K utterances from 12K conversations from the chat logs of 1.9K completed Dota 2 matches. We propose a robust dual semantic-level toxicity framework, which handles utterance and token-level patterns, and rich contextual chatting history. Accompanying the dataset is a thorough in-game toxicity analysis, which provides comprehensive understanding of context at utterance, token, and dual levels. Inspired by NLU, we also apply its metrics to the toxicity detection tasks for assessing toxicity and game-specific aspects. We evaluate strong NLU models on CONDA, providing fine-grained results for different intent classes and slot classes. Furthermore, we examine the coverage of toxicity nature in our dataset by comparing it with other toxicity datasets.