 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Based Proximity Matrix Factorization for Node Embedding
Paper and Code
Jun 10, 2021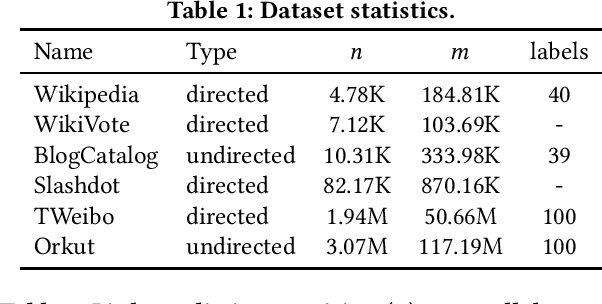
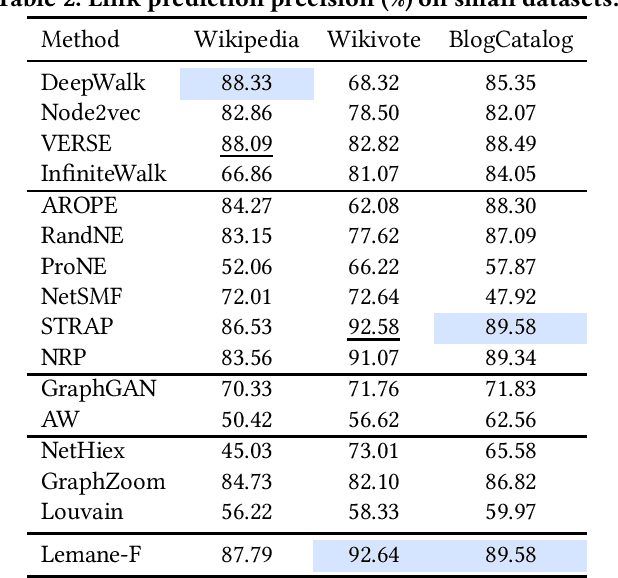
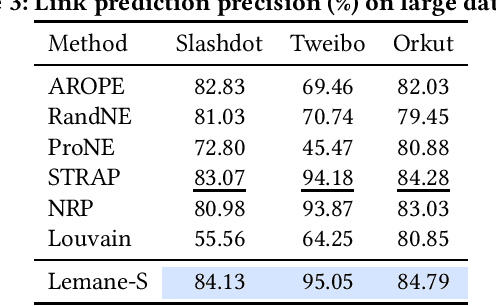
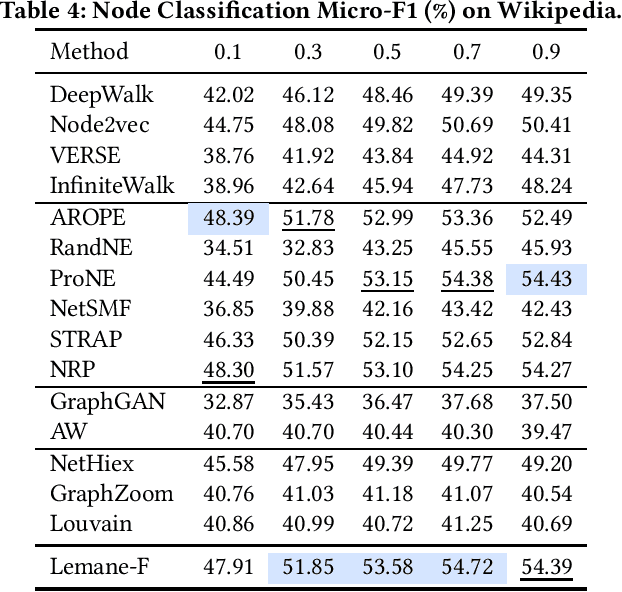
Node embedding learns a low-dimensional representation for each node in the graph. Recent progress on node embedding shows that proximity matrix factorization methods gain superb performance and scale to large graphs with millions of nodes. Existing approaches first define a proximity matrix and then learn the embeddings that fit the proximity by matrix factorization. Most existing matrix factorization methods adopt the same proximity for different tasks, while it is observed that different tasks and datasets may require different proximity, limiting their representation power. Motivated by this, we propose {\em Lemane}, a framework with trainable proximity measures, which can be learned to best suit the datasets and tasks at hand automatically. Our method is end-to-end, which incorporates differentiable SVD in the pipeline so that the parameters can be trained via backpropagation. However, this learning process is still expensive on large graphs. To improve the scalability, we train proximity measures only on carefully subsampled graphs, and then apply standard proximity matrix factorization on the original graph using the learned proximity. Note that, computing the learned proximities for each pair is still expensive for large graphs, and existing techniques for computing proximities are not applicable to the learned proximities. Thus, we present generalized push techniques to make our solution scalable to large graphs with millions of nodes. Extensive experiments show that our proposed solution outperforms existing solutions on both link prediction and node classification tasks on almost all datasets.