 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Relevant and Coherent Dialogue Responses using Self-separated Conditional Variational AutoEncoders
Paper and Code
Jun 07, 2021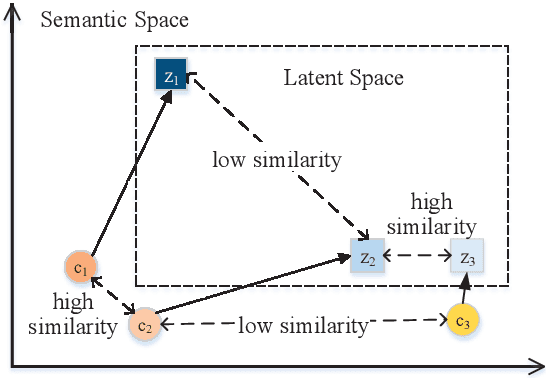
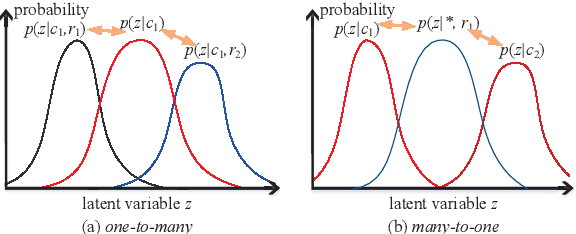
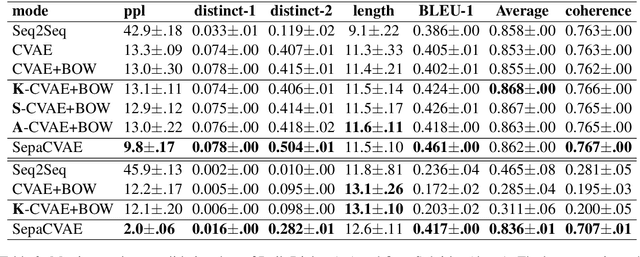
Conditional Variational AutoEncoder (CVAE) effectively increases the diversity and informativeness of responses in open-ended dialogue generation tasks through enriching the context vector with sampled latent variables. However, due to the inherent one-to-many and many-to-one phenomena in human dialogues, the sampled latent variables may not correctly reflect the contexts' semantics, leading to irrelevant and incoherent generated responses. To resolve this problem, we propose Self-separated Conditional Variational AutoEncoder (abbreviated as SepaCVAE) that introduces group information to regularize the latent variables, which enhances CVAE by improving the responses' relevance and coherence while maintaining their diversity and informativeness. SepaCVAE actively divides the input data into groups, and then widens the absolute difference between data pairs from distinct groups, while narrowing the relative distance between data pairs in the same group. Empirical results from automatic evaluation and detailed analysis demonstrate that SepaCVAE can significantly boost responses in well-established open-domain dialogue datasets.