 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow to Adapt Your Pretrained Multilingual Model to 1600 Languages
Paper and Code
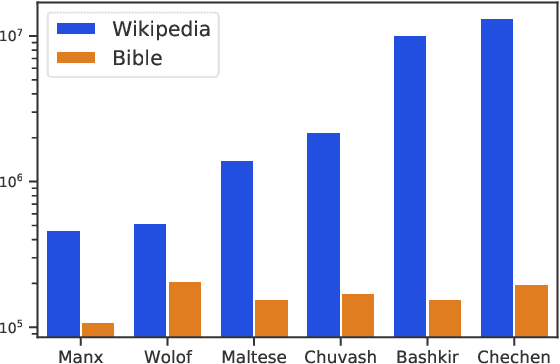
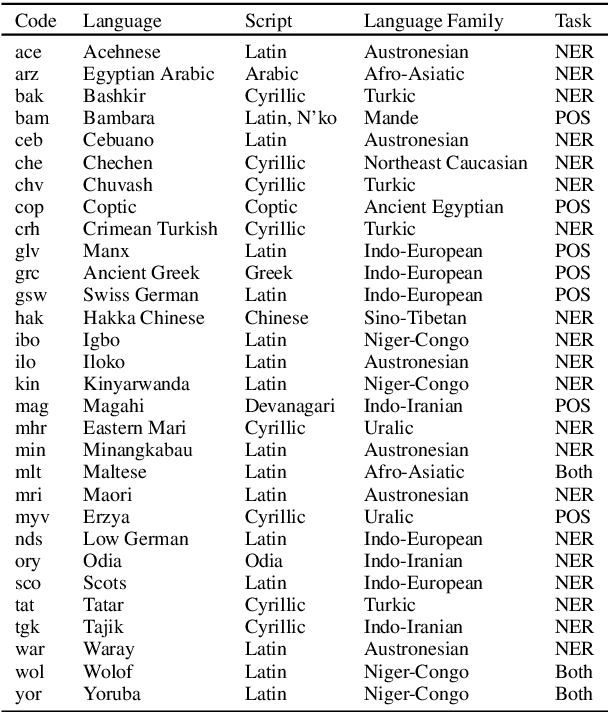
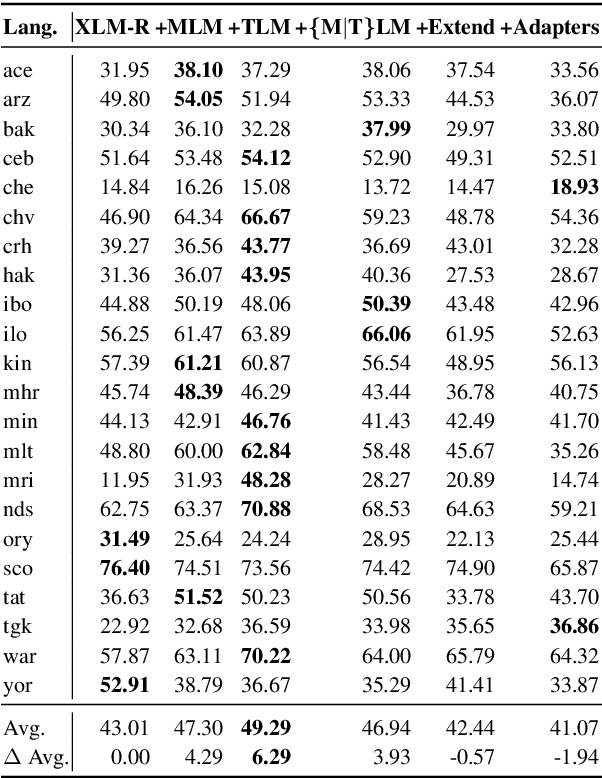
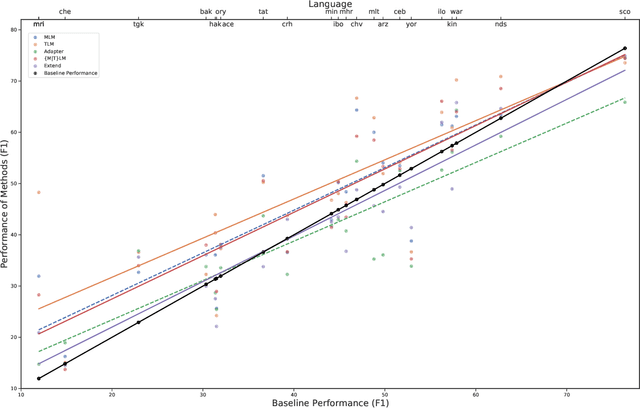
Pretrained multilingual models (PMMs) enable zero-shot learning via cross-lingual transfer, performing best for languages seen during pretraining. While methods exist to improve performance for unseen languages, they have almost exclusively been evaluated using amounts of raw text only available for a small fraction of the world's languages. In this paper, we evaluate the performance of existing methods to adapt PMMs to new languages using a resource available for over 1600 languages: the New Testament. This is challenging for two reasons: (1) the small corpus size, and (2) the narrow domain. While performance drops for all approaches, we surprisingly still see gains of up to $17.69\%$ accuracy for part-of-speech tagging and $6.29$ F1 for NER on average over all languages as compared to XLM-R. Another unexpected finding is that continued pretraining, the simplest approach, performs best. Finally, we perform a case study to disentangle the effects of domain and size and to shed light on the influence of the finetuning source language.