 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscovering Diverse Nearly Optimal Policies withSuccessor Features
Paper and Code
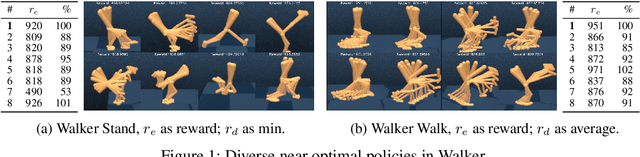


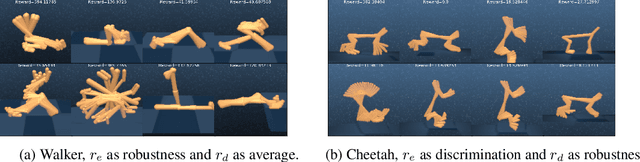
Finding different solutions to the same problem is a key aspect of intelligence associated with creativity and adaptation to novel situations. In reinforcement learning, a set of diverse policies can be useful for exploration, transfer, hierarchy, and robustness. We propose Diverse Successive Policies, a method for discovering policies that are diverse in the space of Successor Features, while assuring that they are near optimal. We formalize the problem as a Constrained Markov Decision Process (CMDP) where the goal is to find policies that maximize diversity, characterized by an intrinsic diversity reward, while remaining near-optimal with respect to the extrinsic reward of the MDP. We also analyze how recently proposed robustness and discrimination rewards perform and find that they are sensitive to the initialization of the procedure and may converge to sub-optimal solutions. To alleviate this, we propose new explicit diversity rewards that aim to minimize the correlation between the Successor Features of the policies in the set. We compare the different diversity mechanisms in the DeepMind Control Suite and find that the type of explicit diversity we are proposing is important to discover distinct behavior, like for example different locomotion patterns.