Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhance Multimodal Model Performance with Data Augmentation: Facebook Hateful Meme Challenge Solution
Paper and Code


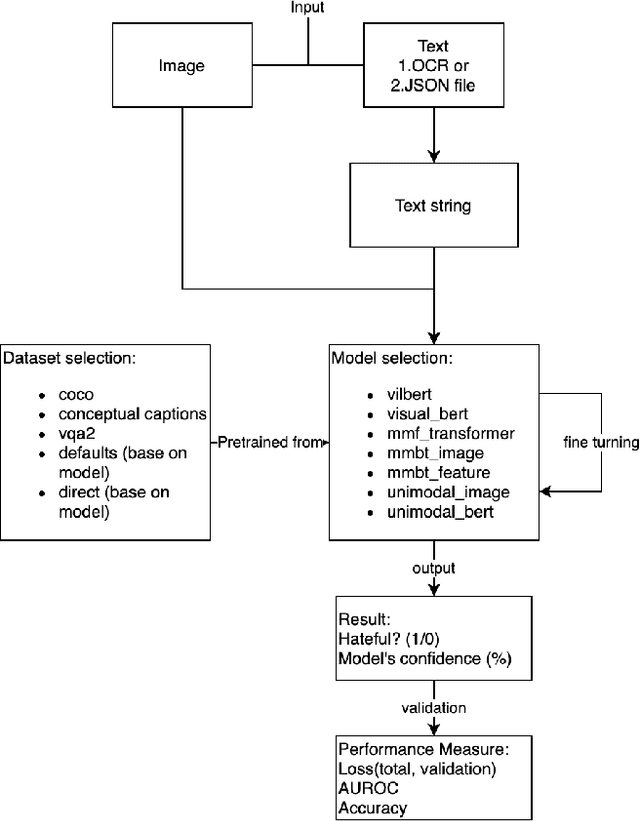
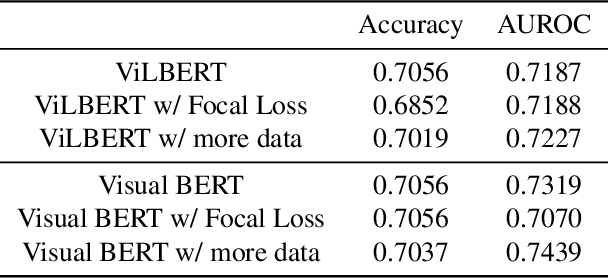
Hateful content detection is one of the areas where deep learning can and should make a significant difference. The Hateful Memes Challenge from Facebook helps fulfill such potential by challenging the contestants to detect hateful speech in multi-modal memes using deep learning algorithms. In this paper, we utilize multi-modal, pre-trained models VilBERT and Visual BERT. We improved models' performance by adding training datasets generated from data augmentation. Enlarging the training data set helped us get a more than 2% boost in terms of AUROC with the Visual BERT model. Our approach achieved 0.7439 AUROC along with an accuracy of 0.7037 on the challenge's test set, which revealed remarkable progress.
* Our code is available at:
https://github.gatech.edu/yli3297/hateful_challenge
View paper on