 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Computational Complexity of ReLU Network Training Parameterized by Data Dimensionality
Paper and Code
May 31, 2021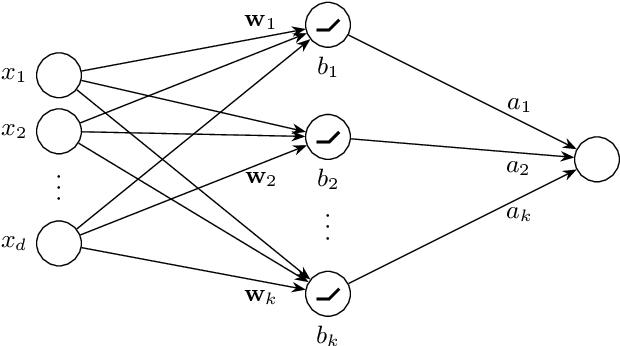

Understanding the computational complexity of training simple neural networks with rectified linear units (ReLUs) has recently been a subject of intensive research. Closing gaps and complementing results from the literature, we present several results on the parameterized complexity of training two-layer ReLU networks with respect to various loss functions. After a brief discussion of other parameters, we focus on analyzing the influence of the dimension $d$ of the training data on the computational complexity. We provide running time lower bounds in terms of W[1]-hardness for parameter $d$ and prove that known brute-force strategies are essentially optimal (assuming the Exponential Time Hypothesis). In comparison with previous work, our results hold for a broad(er) range of loss functions, including $\ell^p$-loss for all $p\in[0,\infty]$. In particular, we extend a known polynomial-time algorithm for constant $d$ and convex loss functions to a more general class of loss functions, matching our running time lower bounds also in these cases.