 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCounterfactual Interventions Reveal the Causal Effect of Relative Clause Representations on Agreement Prediction
Paper and Code
May 19, 2021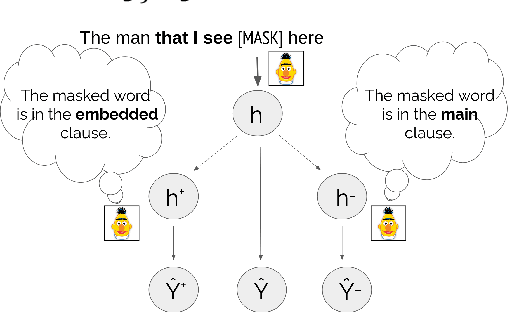

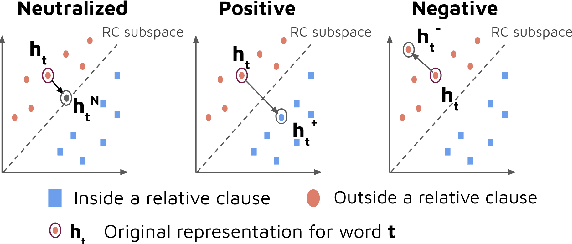
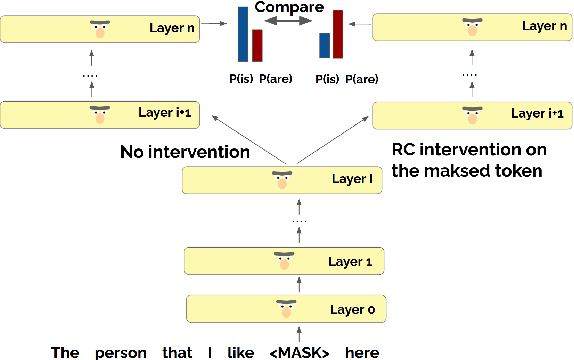
When language models process syntactically complex sentences, do they use abstract syntactic information present in these sentences in a manner that is consistent with the grammar of English, or do they rely solely on a set of heuristics? We propose a method to tackle this question, AlterRep. For any linguistic feature in the sentence, AlterRep allows us to generate counterfactual representations by altering how this feature is encoded, while leaving all other aspects of the original representation intact. Then, by measuring the change in a models' word prediction with these counterfactual representations in different sentences, we can draw causal conclusions about the contexts in which the model uses the linguistic feature (if any). Applying this method to study how BERT uses relative clause (RC) span information, we found that BERT uses information about RC spans during agreement prediction using the linguistically correct strategy. We also found that counterfactual representations generated for a specific RC subtype influenced the number prediction in sentences with other RC subtypes, suggesting that information about RC boundaries was encoded abstractly in BERT's representation.