 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNLP-IIS@UT at SemEval-2021 Task 4: Machine Reading Comprehension using the Long Document Transformer
Paper and Code
May 08, 2021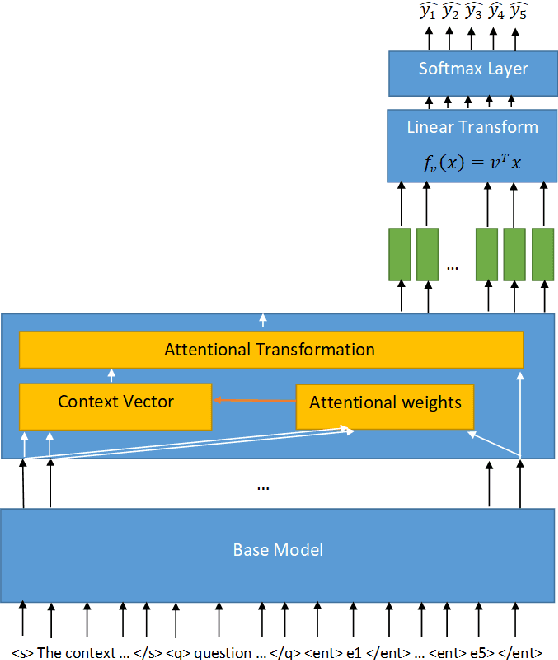
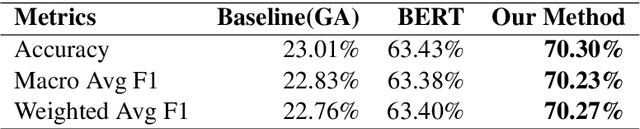
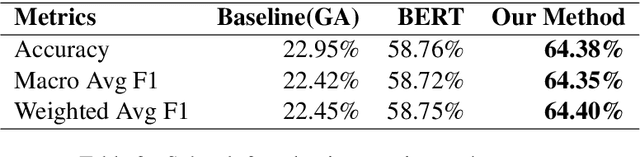
This paper presents a technical report of our submission to the 4th task of SemEval-2021, titled: Reading Comprehension of Abstract Meaning. In this task, we want to predict the correct answer based on a question given a context. Usually, contexts are very lengthy and require a large receptive field from the model. Thus, common contextualized language models like BERT miss fine representation and performance due to the limited capacity of the input tokens. To tackle this problem, we used the Longformer model to better process the sequences. Furthermore, we utilized the method proposed in the Longformer benchmark on Wikihop dataset which improved the accuracy on our task data from 23.01% and 22.95% achieved by the baselines for subtask 1 and 2, respectively, to 70.30% and 64.38%.