 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre Pre-trained Convolutions Better than Pre-trained Transformers?
Paper and Code
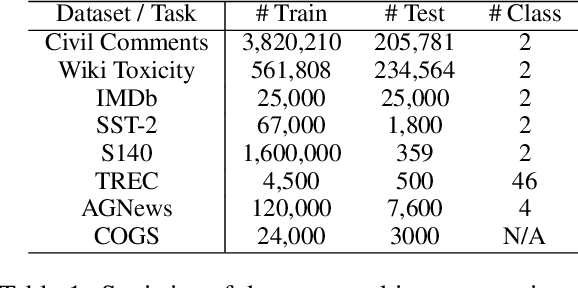
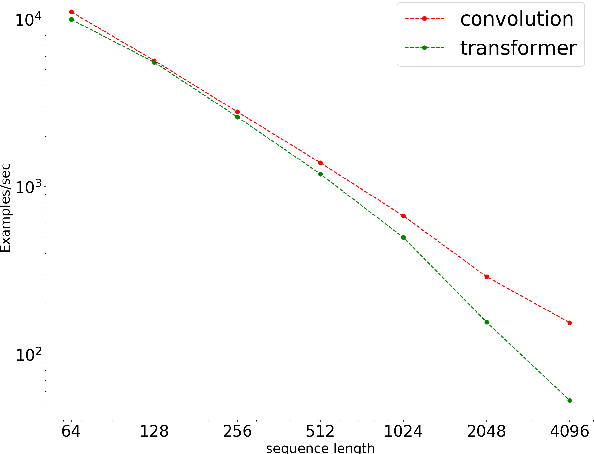
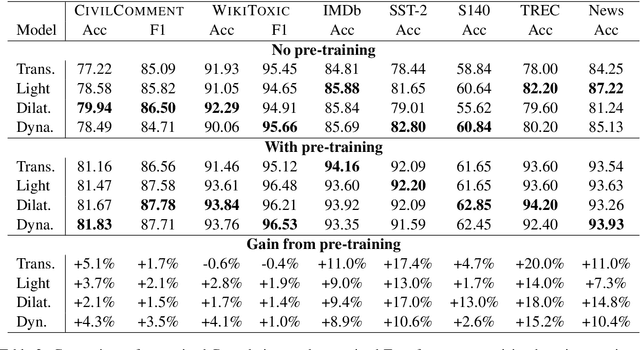
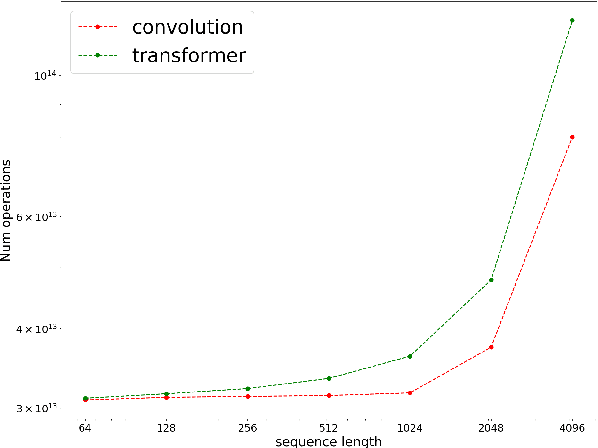
In the era of pre-trained language models, Transformers are the de facto choice of model architectures. While recent research has shown promise in entirely convolutional, or CNN, architectures, they have not been explored using the pre-train-fine-tune paradigm. In the context of language models, are convolutional models competitive to Transformers when pre-trained? This paper investigates this research question and presents several interesting findings. Across an extensive set of experiments on 8 datasets/tasks, we find that CNN-based pre-trained models are competitive and outperform their Transformer counterpart in certain scenarios, albeit with caveats. Overall, the findings outlined in this paper suggest that conflating pre-training and architectural advances is misguided and that both advances should be considered independently. We believe our research paves the way for a healthy amount of optimism in alternative architectures.