 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Question Answering Model Robustness with Synthetic Adversarial Data Generation
Paper and Code
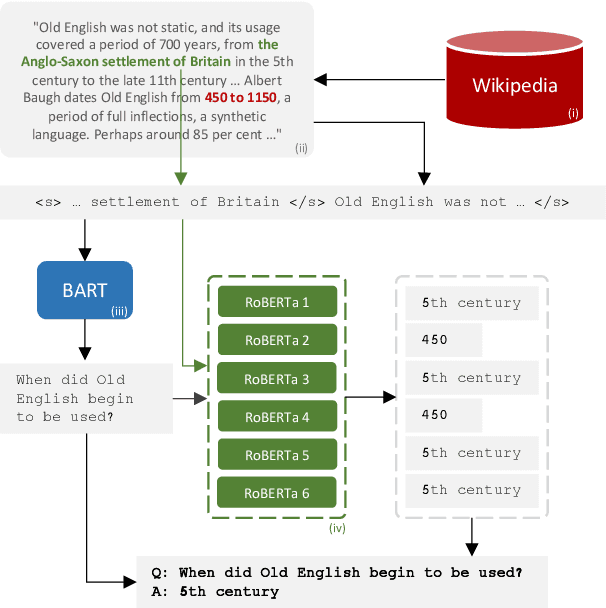
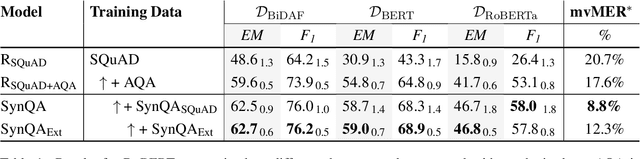
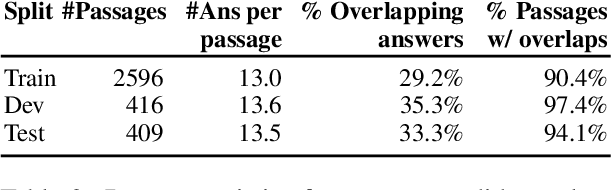
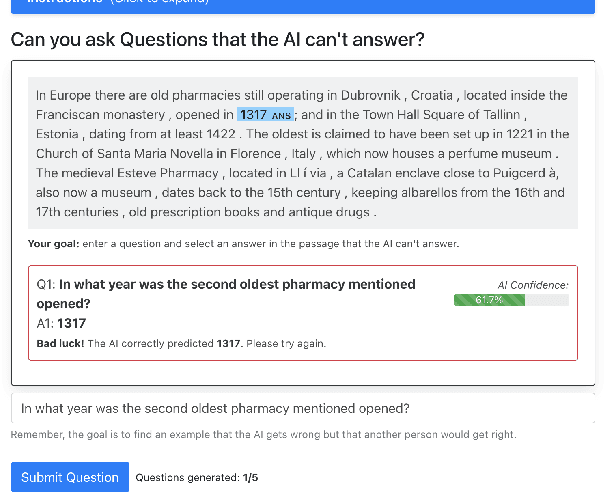
Despite the availability of very large datasets and pretrained models, state-of-the-art question answering models remain susceptible to a variety of adversarial attacks and are still far from obtaining human-level language understanding. One proposed way forward is dynamic adversarial data collection, in which a human annotator attempts to create examples for which a model-in-the-loop fails. However, this approach comes at a higher cost per sample and slower pace of annotation, as model-adversarial data requires more annotator effort to generate. In this work, we investigate several answer selection, question generation, and filtering methods that form a synthetic adversarial data generation pipeline that takes human-generated adversarial samples and unannotated text to create synthetic question-answer pairs. Models trained on both synthetic and human-generated data outperform models not trained on synthetic adversarial data, and obtain state-of-the-art results on the AdversarialQA dataset with overall performance gains of 3.7F1. Furthermore, we find that training on the synthetic adversarial data improves model generalisation across domains for non-adversarial data, demonstrating gains on 9 of the 12 datasets for MRQA. Lastly, we find that our models become considerably more difficult to beat by human adversaries, with a drop in macro-averaged validated model error rate from 17.6% to 8.8% when compared to non-augmented models.